Kaizen #123 Data Synchronization from a third party application
Welcome back to the Kaizen series!
In last week's post in the Kaizen series, we discussed one-way data synchronization from Zoho CRM to a legacy application, utilizing Zoho CRM's Bulk Read API and Notification API. This week, we will discuss data synchronization from a third party app to Zoho CRM.
The APIs available in Zoho CRM to insert, update or upsert records are :
1) Insert, Update, and Upsert Records APIs
These are synchronous APIs that are used to perform create, update or upsert operations for up to 100 records in a Zoho CRM module. While the Insert Records API and Update Records API is used to create and update a record respectively, the Upsert Records API is used to upsert (insert or update) a record depending on the availability of the record in your org . In Upsert Records API, the system checks for duplicate records based on the values in the duplicate_check_fields json array in the input json. If the record is already present, it gets updated. If not, the record is inserted. You will get the status of these operations immediately. Read more about the Upsert Records API in this Kaizen post.
2) Bulk Write API
The Bulk Write API is an asynchronous API that is used to perform create/update/upsert operations for up to 25K records in a Zoho CRM module. A background job will be scheduled in Zoho CRM. You can check the status of the scheduled job using the Bulk Write Job Details API. Alternatively, you can configure a callback URL when you schedule the job. The details of the Bulk Write Job result are posted on the callback URL upon successful completion or failure of the job. This bulk write API involves the following steps:
- Preparing the CSV input file
- Uploading the CSV file
- Creating a bulk write job
- Checking the job's status
- Downloading the result
To learn more about these steps in the Bulk Write API and about the Bulk Write API in general, refer to the Kaizen post on the Bulk Write API.
Insert, Update, Upsert Records | Bulk Write API |
Insert, update, or upsert up to 100 records per API call. | Insert, update, or upsert up to 25000 records per API call. |
The response is available instantly. | The response to the Bulk Write API request will not be available immediately. You can check the status of the job by polling for it, or you can wait for the status to be available in the callback URL after the job has completed. |
These APIs consume one credit per 10 records. | Bulk Write API consumes 500 credits per API call. |
Input should be in JSON format | The input file should be in CSV format. |
Let us now examine four different scenarios for record insertion in a module, specifically with varying quantities: 100, 2000, 5000, and 25000 records, and discover how these APIs perform in terms of number of API calls and credits consumed.
Number of Records | Insert,Update or Upsert Records API | Bulk Write API |
100 | 1 API Call 10 API Credits | 1 API Call 500 API Credits |
2000 | 20 API Calls 200 API Credits | 1 API Call 500 API Credits |
5000 | 50 API Calls 500 API Credits | 1 API Call 500 API Credits |
25000 | 250 API Calls 2500 API Credits | 1 API Call 500 API Credits |
Clearly, if you have more than 5000 records, it is advisable to use the bulk write API, given that you are ok with the operation being run asynchronously. If you want instant results, you should use insert/update/upsert APIs. However, more API credits will be consumed in this case.
Data Sync
Consider an e-commerce company where the Order management team uses a legacy system and the Accounts team uses Zoho CRM. To ensure that the Accounts team works with near real-time data in Zoho CRM, data synchronization from the legacy application is essential. Assume that in Zoho CRM, there is a custom module named "Orders" that contains the details from the legacy system. Imagine that you are in charge of the data synchronization between Zoho CRM and the legacy system. How should you call these APIs to achieve this synchronization? The synchronization process involves two steps.
Step 1: Initial Data Sync : Initial data sync from the legacy system to Zoho CRM.
Step 2: Subsequent Data Sync : Push any new orders or updated orders to Zoho CRM.
The solution we propose here is one of the many ways in which the data sync can be achieved.
This solution is built on the below three key points:
1) Unique field in Order Module: Maintain a unique field "parent_id" in the "Orders" module. The unique identifier of the orders in your legacy system should be mapped to this parent_id field. In create bulk write job, this can be achieved by the section field_mappings. For ensuring correct working of upsert operations, you can make use of "find_by" field inside resource JSON Array in the Create Bulk Write Job API Request. You should provide the value of "find_by" as the unique field "parent_id" . To read more about find_by field refer to Create Bulk Write Job page.
2) Sync Flag in the Orders table in legacy system: For the sync, maintain a flag in your legacy system orders table for indicating whether the record is synced with Zoho CRM or not. Once the sync is done, update the flag to true. Whenever a record is modified or sync fails, the flag value should be updated to false. This ensures that in case a record that is synced gets updated during the initial sync process, this flag column helps us re-sync this record again.
3) Grouping of data to batches: For initial sync, the data volume in the table will be huge. So they have to be batched in a group of 25k records. This grouping can be done based on sorting the table with a particular column & filtering records based on the sync column with criteria sync=false.
Step 1: Initial Data Sync
Since you have multiple batches of 25k records, you have to iterate them one by one and send them to the Bulk Write API.
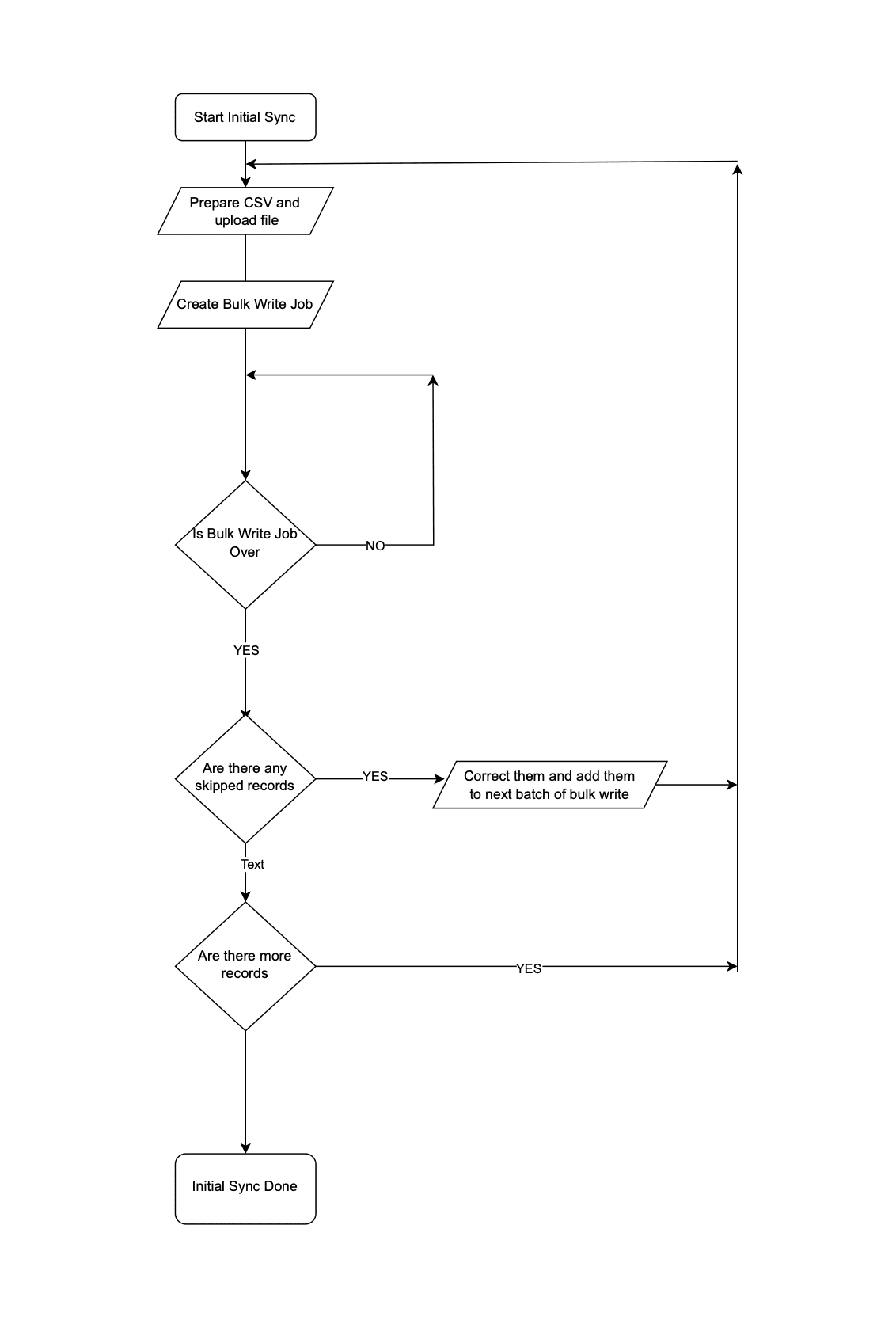 Initial Data Sync
Initial Data SyncStep 2: Subsequent Data Sync
The Order Management team continues to use the legacy application, leading to continuous creation or update of records in the Orders module.
It is not recommended to invoke Upsert Records API whenever an operation happens in Orders in the legacy system. Subsequent data syncs can be done in two ways: either by (a)near real-time sync or (b) Interval based sync.
(a) Near Real-time Sync
As we want near real-time data in Zoho CRM, it is ok for the records that are updated in the legacy system from last synchronization to be unavailable in Zoho CRM for 10 minutes.
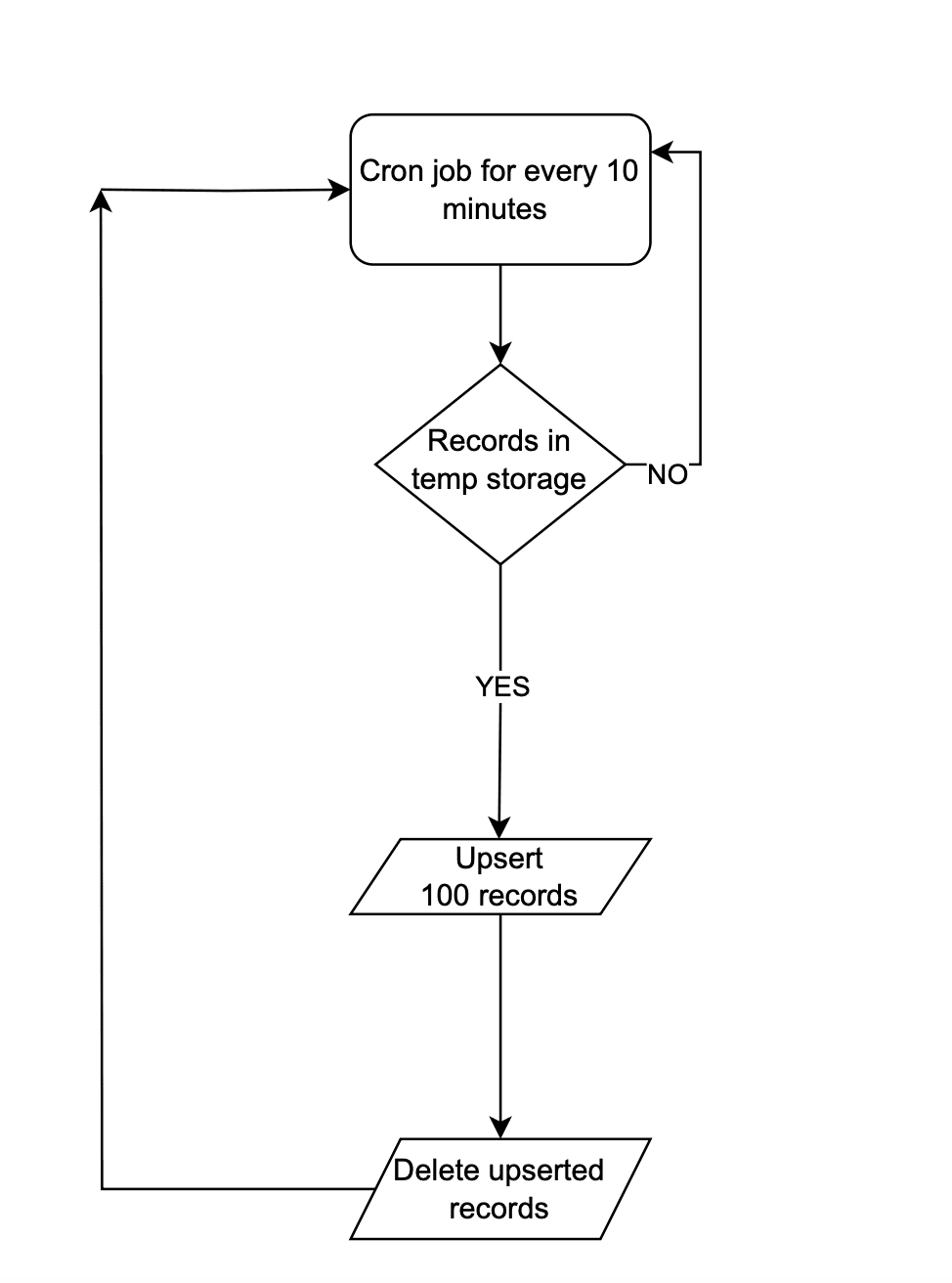 Near Real-time Sync
Near Real-time SyncInstead of making API calls to Zoho CRM on every data operation, store the data in a temporary data store like a DB table or Redis. Once 100 records are accumulated in that data-store, the Upsert Records API can be promptly invoked with all these record details and followed by emptying of the data store. This approach will lead to lower consumption of API credits.
There are chances that in a period of 10 mins, 100 record operations may not happen. Scheduler jobs or CRON jobs can be created to handle the records in the data store to update records to Zoho CRM. Once these records are handled, the data store should be emptied.
(b) Interval based synchronization
For interval based synchronization, schedule bulk write API calls at suitable intervals to upsert the Orders module in Zoho CRM. Whenever there is a record operation in the legacy table, update the sync flag to "false". At regular intervals, such as every 12 or 24 hours, the bulk write API or Upsert Records API can be employed depending on the volume of the data changes.
We hope you found this article useful. We will be back next week with another interesting topic. If you have any questions, write to us at support@zohocrm.com or let us know in the comment section.
Previous Kaizen Post: Kaizen #122 - Data Synchronization using Bulk Read and Notification APIs