A pipeline execution is called a job, a job tracks the progress of imports, transformations and exports in a pipeline among other stats.
To navigate to the Jobs page, you can click the Jobs tab from the top bar menu.
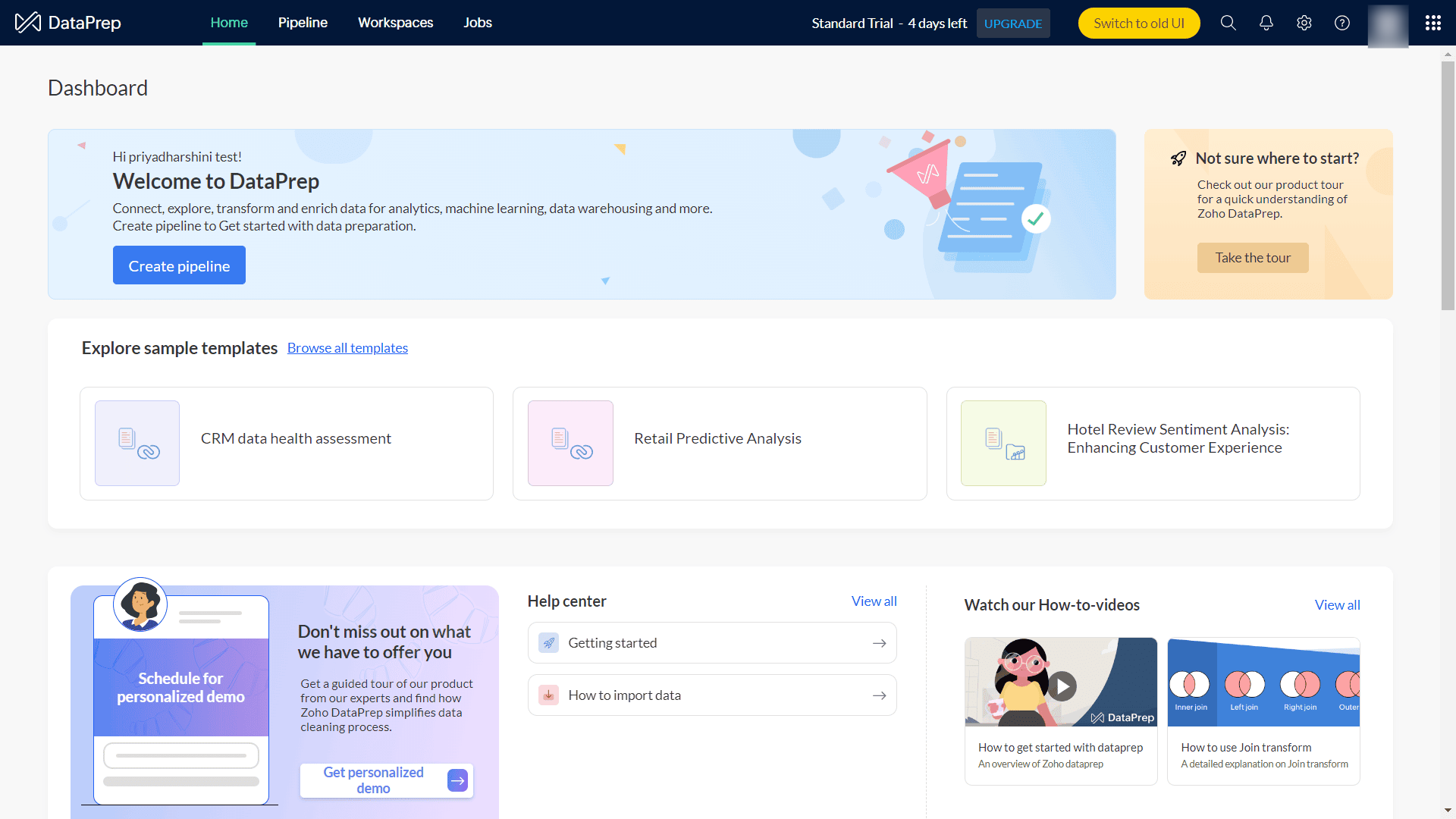
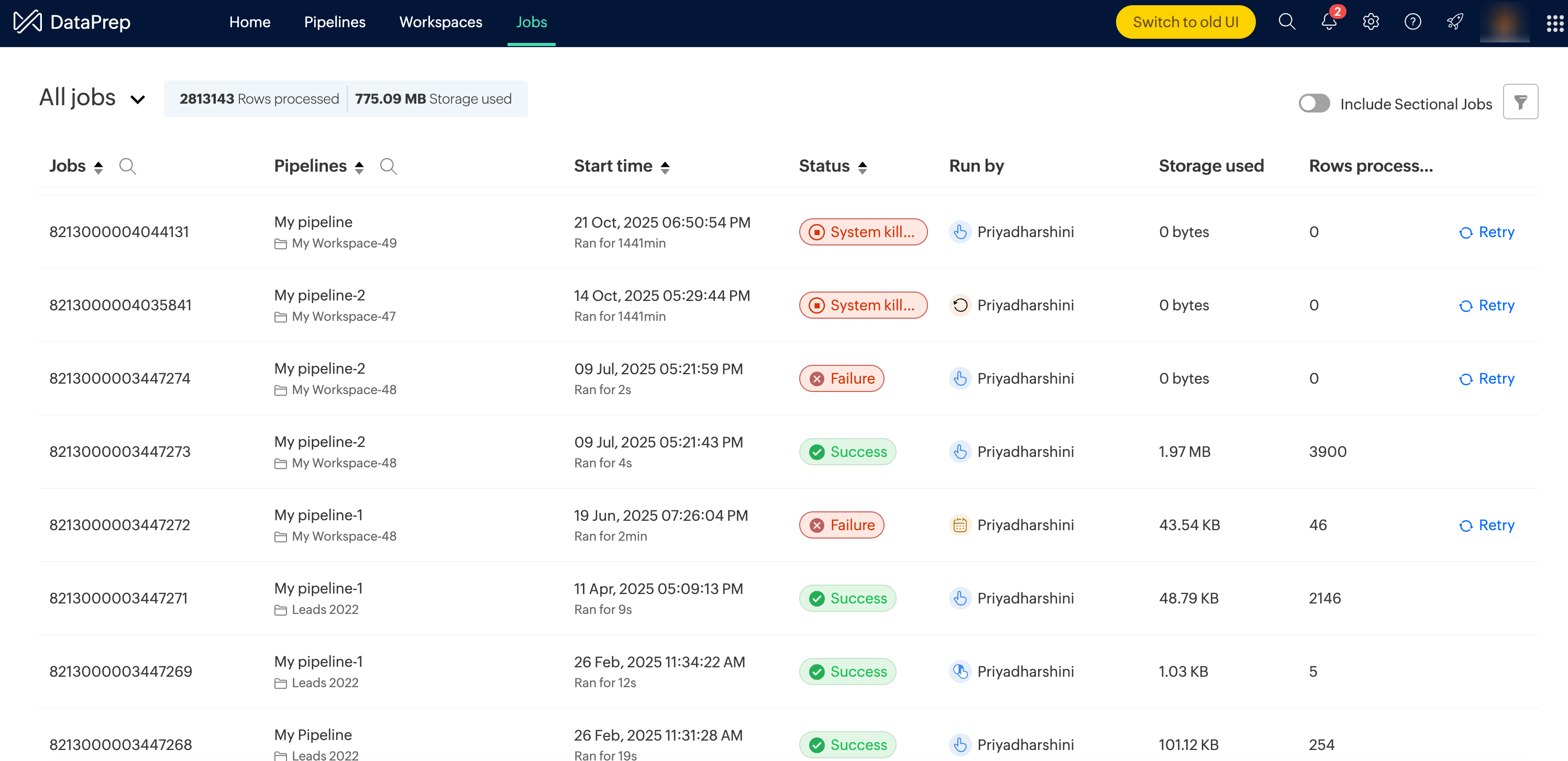
The Jobs tab shows the list of all the jobs executed across all the workspaces in your organization along with the Job ID, the associated pipeline, start and run time, status, run by, storage used, and rows processed.
The jobs list can help you identify the failed pipeline jobs and give users a way to retry the jobs.
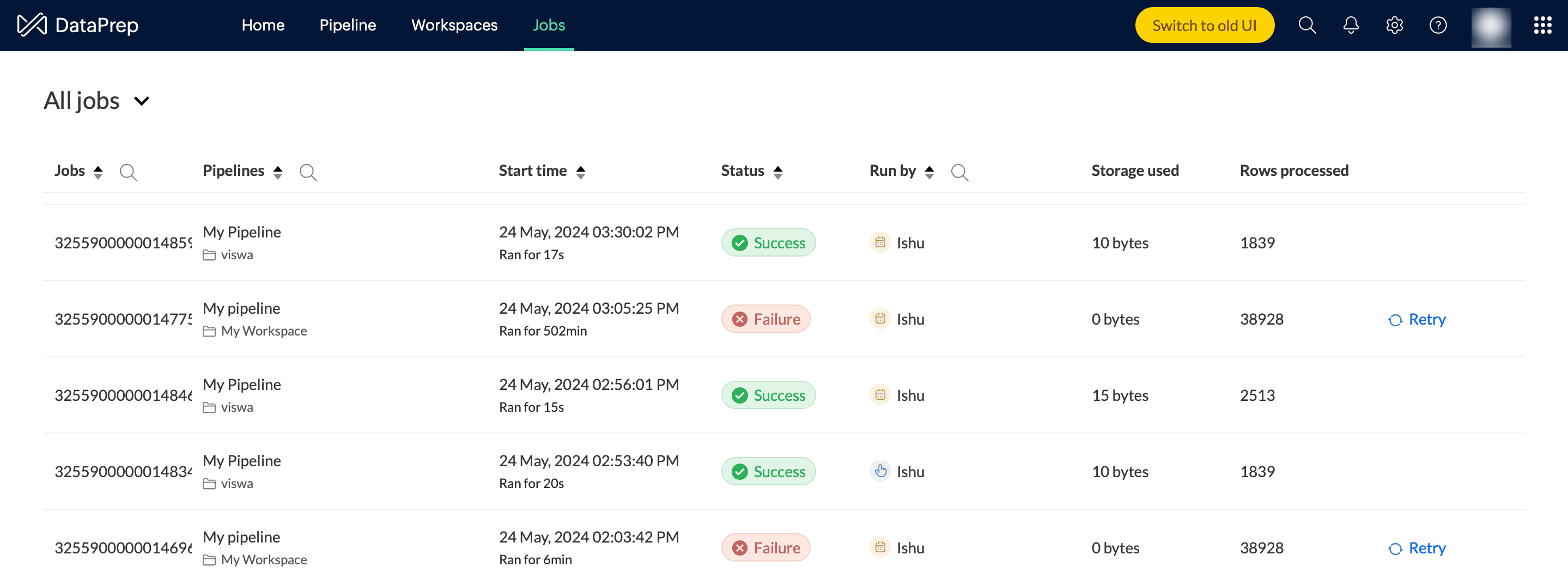
Filter:
You can use the filter dropdown to list the jobs by type: Manual run, Manual run with data(Manual run with refreshed data), Schedule run, Backfill run, Sectional run, Zoho Flow, Webhooks, Reload data and Code executions. To view sectional jobs, you can enable the Include Sectional Jobs toggle.
You can also filter and search on the jobs using filter attributes such as run by, pipeline, workspace, status, and run time. Learn more.
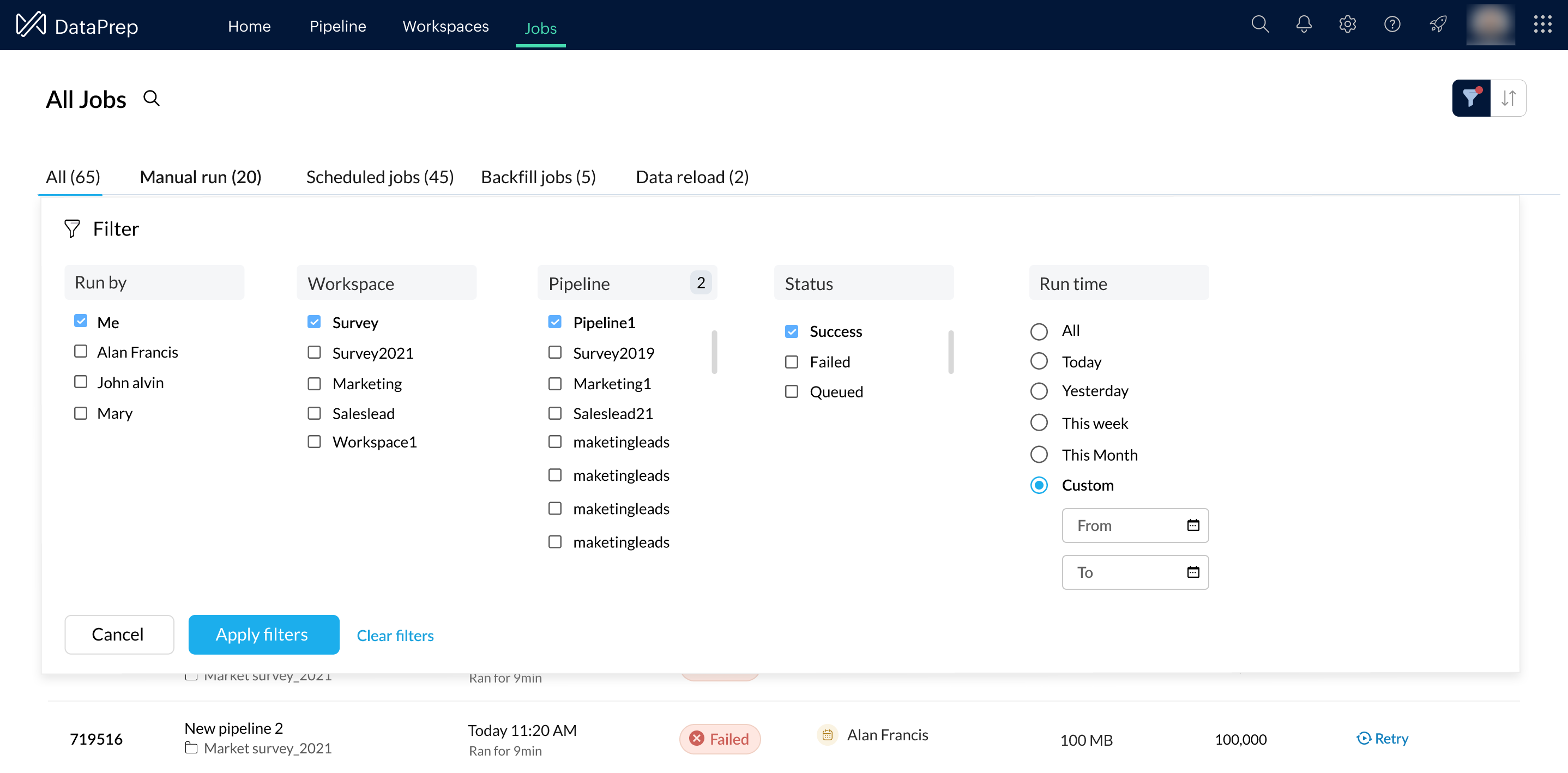
You can also quickly sort your jobs based on pipelines, start time and status using the respective sort icons located at the top of the table header.
To learn more about pipelines and other entities in DataPrep, click here.
Job Summary
Click on a job in the Jobs page to navigate to the Job summary. The Job Summary page displays key execution details of a job, including the Pipeline name, Job status, Run duration, Run by, Storage used, Total rows processed, Data interval, as well as the Start and End time of the job.
 Note: You can also choose the Job history option from the Pipeline builder page and navigate to the Job summary page.
Note: You can also choose the Job history option from the Pipeline builder page and navigate to the Job summary page.
This gives detailed insights into a specific job and visibility into how a pipeline performed from start to finish including overall status, individual stage outcomes, and exported results helping you troubleshoot issues, analyze performance, and verify output quality.
You can click Edit pipeline to modify your pipeline if a job fails or if changes are required. To view all the jobs executed in your pipeline, click the Job history option.
The Job summary shows details of a job in three different tabs: Pipeline flow, Stages and Output.
Pipeline flow
The Pipeline flow tab provides a visual representation of how the pipeline is executed for the selected job. It helps you understand the end-to-end flow of data through the pipeline and quickly verify whether each step was completed successfully.
This tab displays the sequence of pipeline stages, starting from the import source, through the applied transforms, and up to the final export destinations. Each stage in the flow is shown with its execution status, allowing you to easily identify completed, failed, or skipped steps. You can also download all outputs together as a ZIP file using the Download all outputs option.
Click on a Stage in the Pipeline flow to view the rules applied on that particular stage.
Stages
The Stages section in the Job Summary page provides a comprehensive view of how a job was executed across the different stages of the pipeline. It breaks down the execution into Import, Transform, and Export, presenting both a summary and detailed view of each stage. It includes details on the status, rows processed, storage used, start time and end time of the import, transforms applied, and export.
Import
The Import stage displays details of all data sources involved in the job. It shows the overall import status along with the count of successful and failed imports. For each source, the stage provides information such as the import status, number of files imported, number of rows imported, storage used, and time taken to complete the import.
You can click the info icon to view the data source details. This will have the necessary details on the source of the input data which includes source type, parsing details, etc.
The View import configuration option gives you an overview of the import configuration of data sources.
The Transforms section shows a summary of all the transforms executed as part of the job run. It provides an overview of transforms and details such as data quality indicators, rows processed, storage usage, and processing time. This section helps you quickly monitor the progress of transform and identify any failed steps that may require attention.
Click the info icon to view all the rules applied to the data. You can also use the Preview icons to quickly view the output at each stage and download the data from any stage if required.
Export
The Export stage provides details of the final outputs generated by the job. It lists all export destinations along with their execution status, data quality indicators, number of rows exported, storage consumed, and time taken for each export. This stage allows you to verify that the processed data was successfully delivered to the intended destinations.
Click the info icon to view the destination details. You can also use the Preview icons to quickly view the output at each stage and download the data from any stage if required.
Stage status
Here's the snapshot of the status you will see when a job is running.
Success - When a stage runs without any error, this status appears.
Not run- Some imports or stages may not run in cases of manual (existing data) or sectional runs, or when they are not a dependent upstream node. For example, during a sectional run, changes from upstream will be loaded into downstream, but no new imports will take place. As a result, the import stage will not run.
Note: The rows from these stages will not be counted for rows processed calculation.
Cached- Some stages will be cached if the data has been already processed in a previous run, or when they are not a dependent upstream node for this run. For example, consider a pipeline with two independent stages, A and B. If you apply transforms only to A and run the pipeline, B will continue to use its existing data without any updates. In this case, B will be cached.
Note: The rows from the cached stages will not be counted for rows processed calculation.
Queued- The next batch of processing stages will be added in queue during a pipeline run.
Failure - When an erroneous stage fails, this status appears.
Output
In the Output tab, you can view the list of all outputs of the job along with the destinations added, data quality, output stage, rows exported, storage used and time taken to export.
You can click the info icon of each output to view the output details. You can also preview the output data and download the output.
If the export fails due to errors such as the ones below, the invalid values in your data must be fixed.
4. Sometimes, the sample might not contain any invalid values, yet the full data will have them. In this case, please go to the last data preparation stage > In the right-hand side pane, click on the edit icon besides Sample Strategy > Select Errorneous sample and click Apply.
This will surface invalid values in your sample data. Please fix these invalid values and retry the job.