Announcing DataPrep 2.0 Beta!

Being data-driven is an important end goal for all organizations, because when businesses can manage, analyze, and make actionable decisions based on data, they have a competitive advantage.
With that said, how confident are you in making business decisions based on your business data? How clean is your CRM data? Or how much time is spent on manual data cleansing and preparation?
To help you solve these problems, we're pleased to announce the release of the DataPrep 2.0 public beta! With this new version, it's now even easier to build an end-to-end pipeline and have complete control over the quality and movement of your data.
What's new in 2.0?

Visual pipeline builder
The all-new pipeline canvas lets you design a seamless end-to-end data flow. Earlier, you were limited to working with a single dataset at a time—but now data can be fetched from multiple sources, more than one dataset can be prepared and used simultaneously, and the data can be exported to multiple destinations. This helps businesses visualize data flows better, simplify complex workflows, and work with data with more confidence.
Unified scheduling of end-to-end pipelines
A massive upgrade has been made to our scheduling feature. In DataPrep 1.0, the sources and destinations had separate schedules which had to be manually managed by staggering the schedule timing, which was hard. But with 2.0, the scheduling can now be set up at the pipeline level. A single unified schedule can be used to manage imports, processing, and exports for all sources and destinations within the pipeline.
Monitor jobs with ease
With automated pipelines, data transfer happens around the clock. Sometimes, there can be issues with fetching data, and the data transfer can fail. But with jobs, you can easily monitor failed jobs with granular details and identify the points of failure. This ensures your organization doesn't miss out on any valuable data.
Comprehensive version history
Maintain a complete audit trail with version history. Working with data can be challenging; but with the help of this feature, you can easily track changes and run experiments to get more out of your data. Not happy with your experimental changes to data? Easily switch back to the previously published version with the click of a button.
Backfill your data effortlessly
There can be outages in the data pipeline, this can be due to source or destination failure, changes in the data or model requiring changes in the preparation steps, and can take a while to be restored. However there is no easy way to catch up on processing the data during the outage, to solve this we are now introducing the Backfill feature. The backfill feature can be used to fetch data and simulate a scheduled process for a selected period of time. For example, if there was an outage of 2 days on a pipeline that was setup to run every hour. With backfill, you can now create a configuration to process all that data by simulating the schedule process for the missed two days, this will create 48 new jobs that will run in sequence and process the missed data for two days.
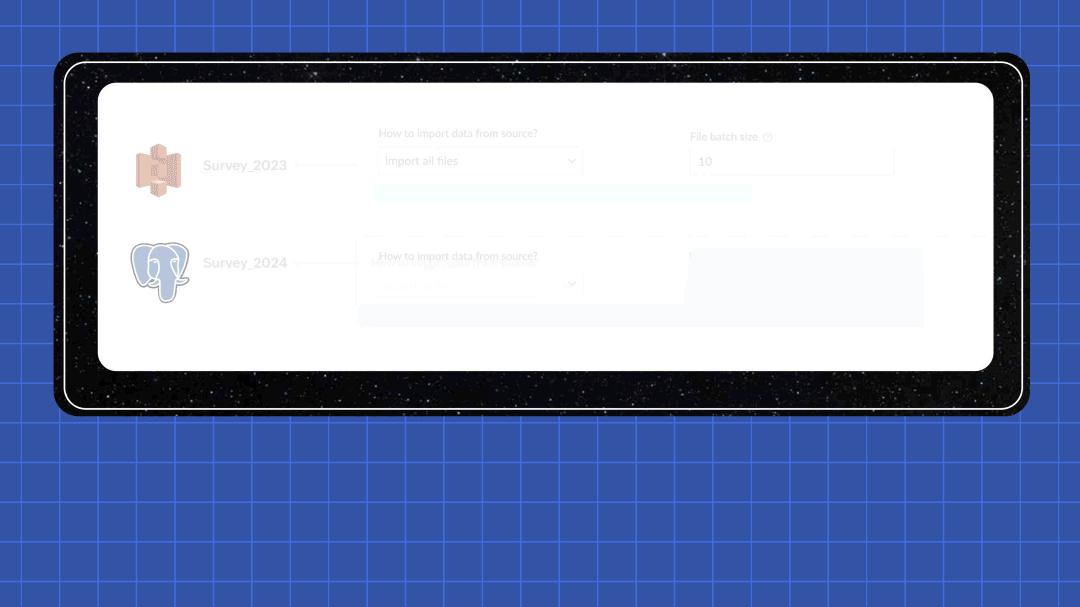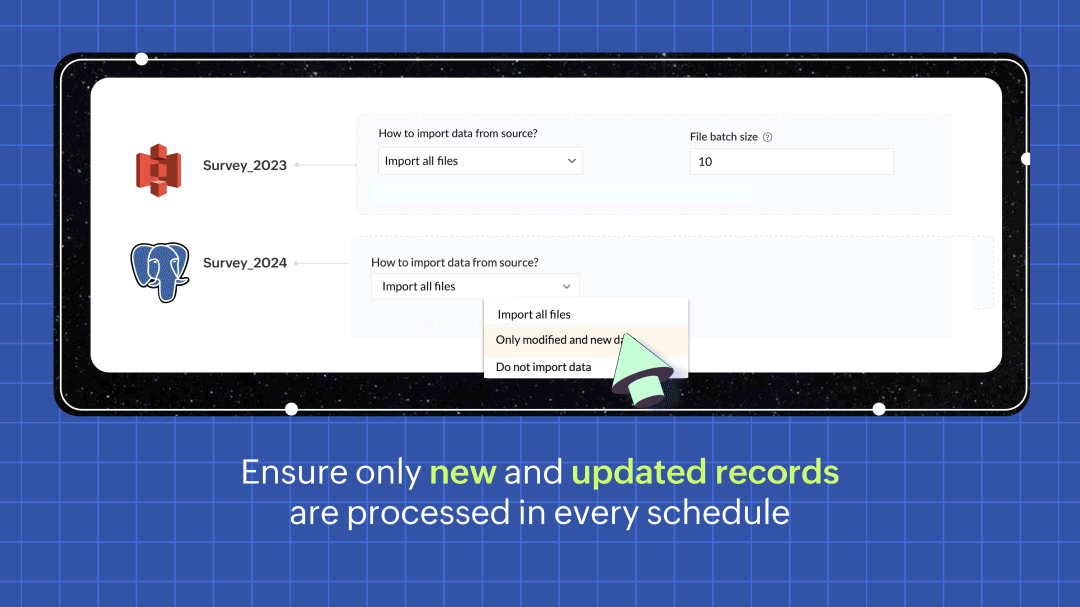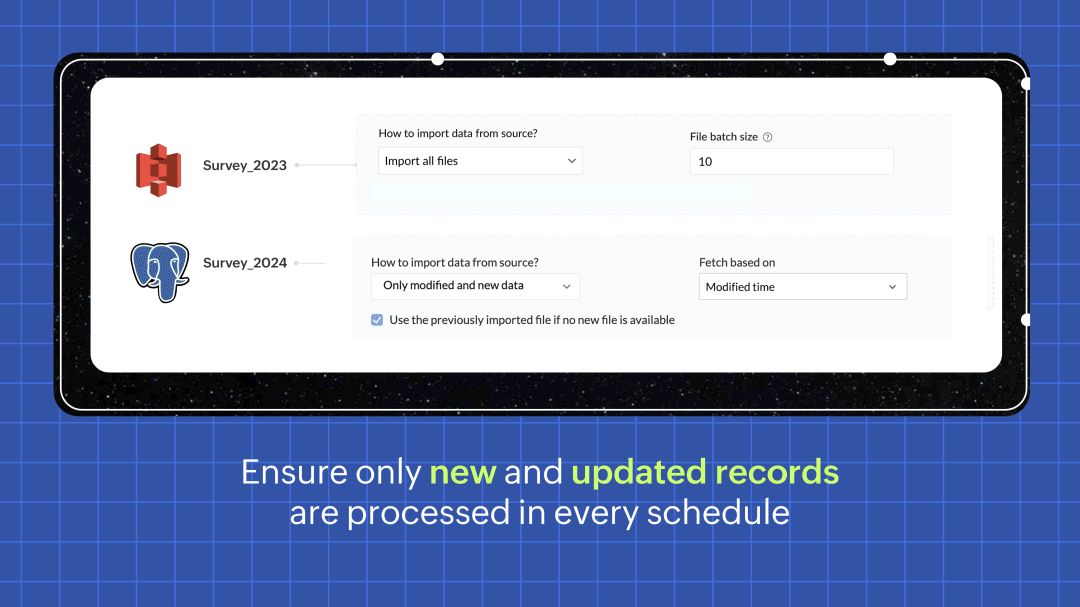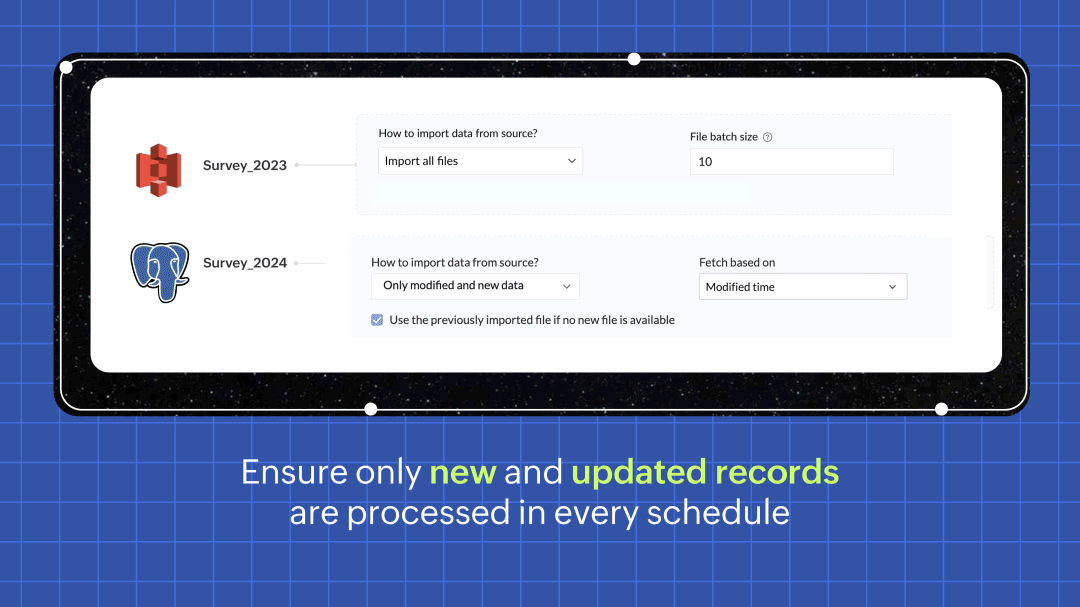
Efficient row processing with incremental fetch
In every scheduled run, choosing the incremental fetch option fetches only the new and updated data from the source for processing. This was available for few sources in 1.0, but we're expanding the support to all data sources in 2.0. Incremental fetch job runs faster, compared to full fetch as only the newly added rows are processed, also making it more cost effective.
Transforms made simple with OpenAI
Our new transforms, powered by OpenAI, help generate complex formulas based on logic written in simple English or transform data based on the sample output given. This simplifies the data preparation process and makes Zoho DataPrep more accessible, even for organizations that don't have a dedicated data analyst team.

Create instant pipelines with templates
We built DataPrep with a vision of helping businesses, big or small, have better access to all their business data—but we understand that the data game can be tricky when you're starting out.
To keep our vision alive and to help everyone start using their business data better, we've built a template gallery based on various business use cases that can easily be used to create a pipeline architecture. Just click on the template to add the formula instantly and transforms needed for the data workflow.
You can also save your own data pipelines as templates to make recreating pipelines easier or to apply the data pipeline over a different set of data. You can also share the data pipelines with your organisation or export them as files to share across different organisations.

New dashboard showcasing your pipeline status
Our new and improved dashboard shows the status of all your pipelines instantly. Easily monitor your scheduled runs, identify failed jobs, and ensure your data is up-to-date in your system.

Make data movement easier with other business applications
We are expanding the list of data connectors supported in Zoho DataPrep and as a start we have released the Zoho Creator integration.

Migrating data into Zoho Creator, as well as seamlessly moving data between various modules within your custom Creator app, has been made easy with DataPrep.
As more organizations are adopting SaaS products in their tech stack, in order to make data more available, we're opening up integrations with HubSpot, Salesforce, and SurveyMonkey, as well as many more Zoho products, in the next couple of months. Stay tuned for more data connectors in Zoho DataPrep!
Can't wait to try DataPrep 2.0?
All our existing customers can access the Beta version right from within their DataPrep home page. The Beta is not available for Zoho One users yet, but if you want to try out the Beta on a standalone account, contact us at customersuccess@zohodataprep.com
Zoho DataPrep is designed to make data preparation and movement easy. With DataPrep 2.0, we have completely revamped our product with the new pipeline builder, unified schedules, pipeline templates and universal incremental fetch that lets you easily manage complex data preparation jobs and data movement. We've also included 50+ other updates to help you clean, prepare, and monitor your business data effortlessly.
Check out all updates in 2.0
Check out all updates in 2.0