OCR自動化

お知らせ:当社は、お客様により充実したサポート情報を迅速に提供するため、本ページのコンテンツは機械翻訳を用いて日本語に翻訳しています。正確かつ最新のサポート情報をご覧いただくには、本内容の英語版を参照してください。
OCR は、画像からテキストを抽出し、他のアプリケーションで簡単に処理・検索・利用できるデジタル形式に変換するための技術です。たとえば、身分証明書(運転免許証やパスポート)に記載された情報を目視で確認しながら手入力する作業は、時間がかかるうえにミスも発生しやすくなります。OCR を自動化に組み込むことで、画像内のテキストを正確にデジタル文字列として抽出し、その後の処理や精査を行い、RPA フローで利用できるようになります。
対応 RPA エージェントプラットフォーム: Windows
主な利用例
- スキャンまたは撮影した身分証(運転免許証、パスポートなど)からテキストを抽出し、照合作業を高速かつ正確に行います。
- 製品画像からシリアル番号、製品コード、ラベル情報を取得し、在庫管理やデータ管理に活用します。
- 画像から車両のナンバープレートを読み取り、セキュリティシステムや駐車場システムで利用します。
- 点検や保守の際に撮影した機器の写真から、シリアル番号、型番、校正日などの重要情報を抽出します。
メモ:
現在の OCR 機能は、画像内の印刷された日本語テキストの認識に対応しています。手書き文字には対応していません。この機能では、画像処理に Tesseract OCR エンジンを使用しています。
OCR でテキストを取得する
設定
変数名:画像から抽出したテキストを格納する出力変数の名前を指定します。この変数は、その後の自動化フローのステップで利用できます。
テンプレート画像パス: 抽出したいデータが画像のどこにあるかをボットに認識させるための参照画像のファイルパスです。これは OCR アクションの設定時にのみ使用されます。
実行画像パス:ワークフロー実行時に、ボットがテキスト抽出の対象として処理する実際の画像ファイルのパスです。ボットはテンプレートファイルで設定した内容と領域情報を使用して、この画像からデータを読み取ります。
画像スケールの設定: 画像の拡大率を指定します(例: 2 は 2 倍、1.5 は 1.5 倍)。スケールを大きくすると、表示とテキストの視認性が向上し、OCR の精度向上にもつながります。1〜10 の範囲で小数値も指定できます。
詳細オプション
画像の色を反転: このオプションを有効にすると、画像の色を反転します。背景に対して文字色が薄い場合などに有効です。
画像の前処理を適用: このオプションを有効にすると、OCR の精度を高めるための標準的な画像前処理を適用します。
抽出対象:
- 画像全体
画像内の印刷されたテキストをすべて 1 つの文字列として抽出します。
- 画像内の特定領域
画像の一部のテキストのみを抽出します。
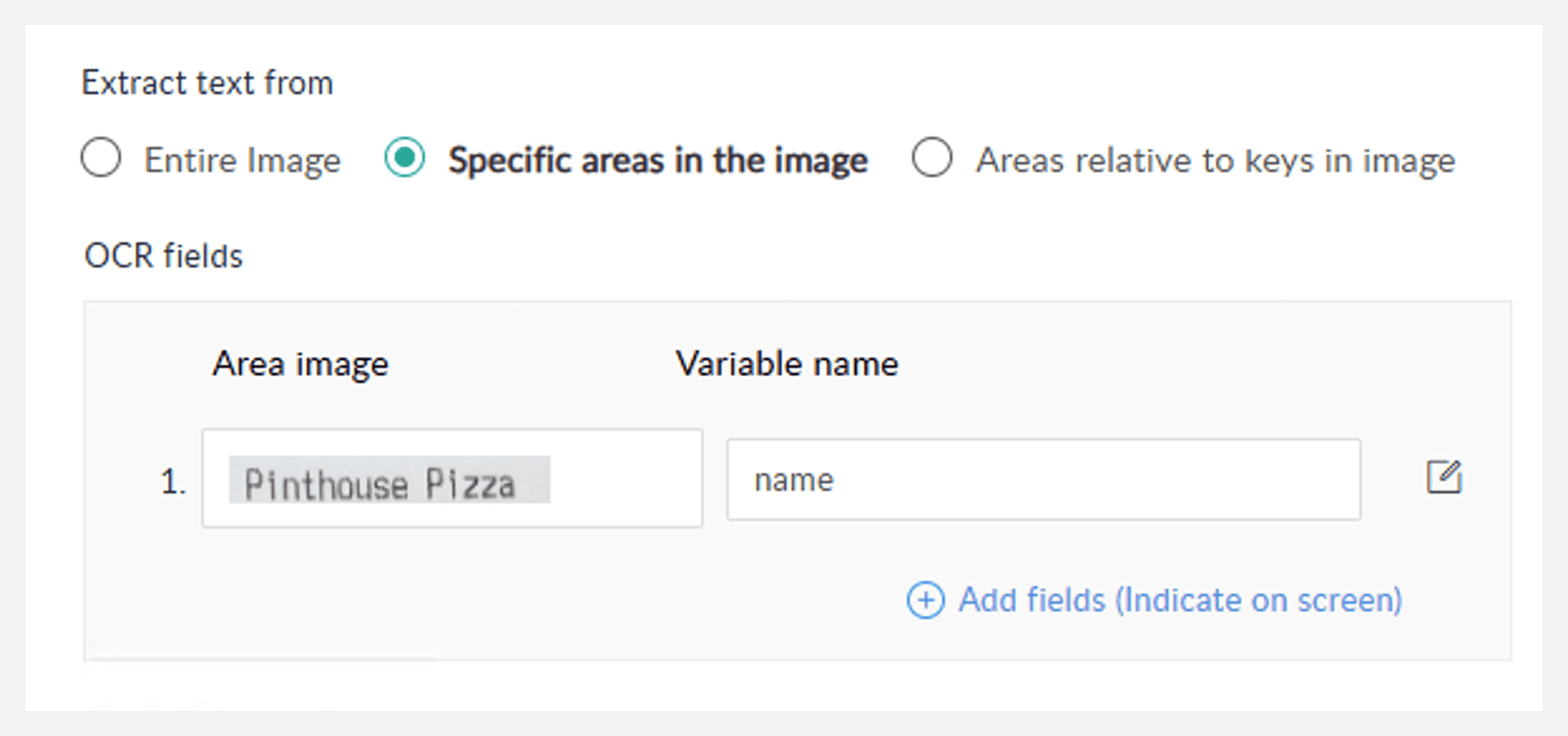 領域画像: 画像内で選択した領域のプレビューです。
領域画像: 画像内で選択した領域のプレビューです。
変数名: 選択した領域から抽出されたテキスト値を保持します。
- 画像内のキーに対する相対領域
画像内に含まれる基準テキスト(キー)をもとにテキストを抽出します。ボットはまず指定されたキー文字列を検出し、そのキーに対する相対位置に基づいて値を抽出します。データ要素の位置が多少変動する場合でも、キーとの相対的な距離(位置関係)を指定することで柔軟に対応できます。
キー文字列:抽出対象領域を検索する際の基準となるテキストです。
変数名: 選択した領域から抽出されたテキスト値を保持します。
詳細設定:
キーの一致パターン:
完全一致: 画像内のテキストが、指定したキー文字列と完全に一致している必要があります。
含むテキスト: 画像内のテキストに、指定したキー文字列がどこかに含まれている必要があります。
テキストが次で始まる:画像内のテキストが、指定したキー文字列で始まっている必要があります。
テキストが次で終わる:画像内のテキストが、指定したキー文字列で終わっている必要があります。
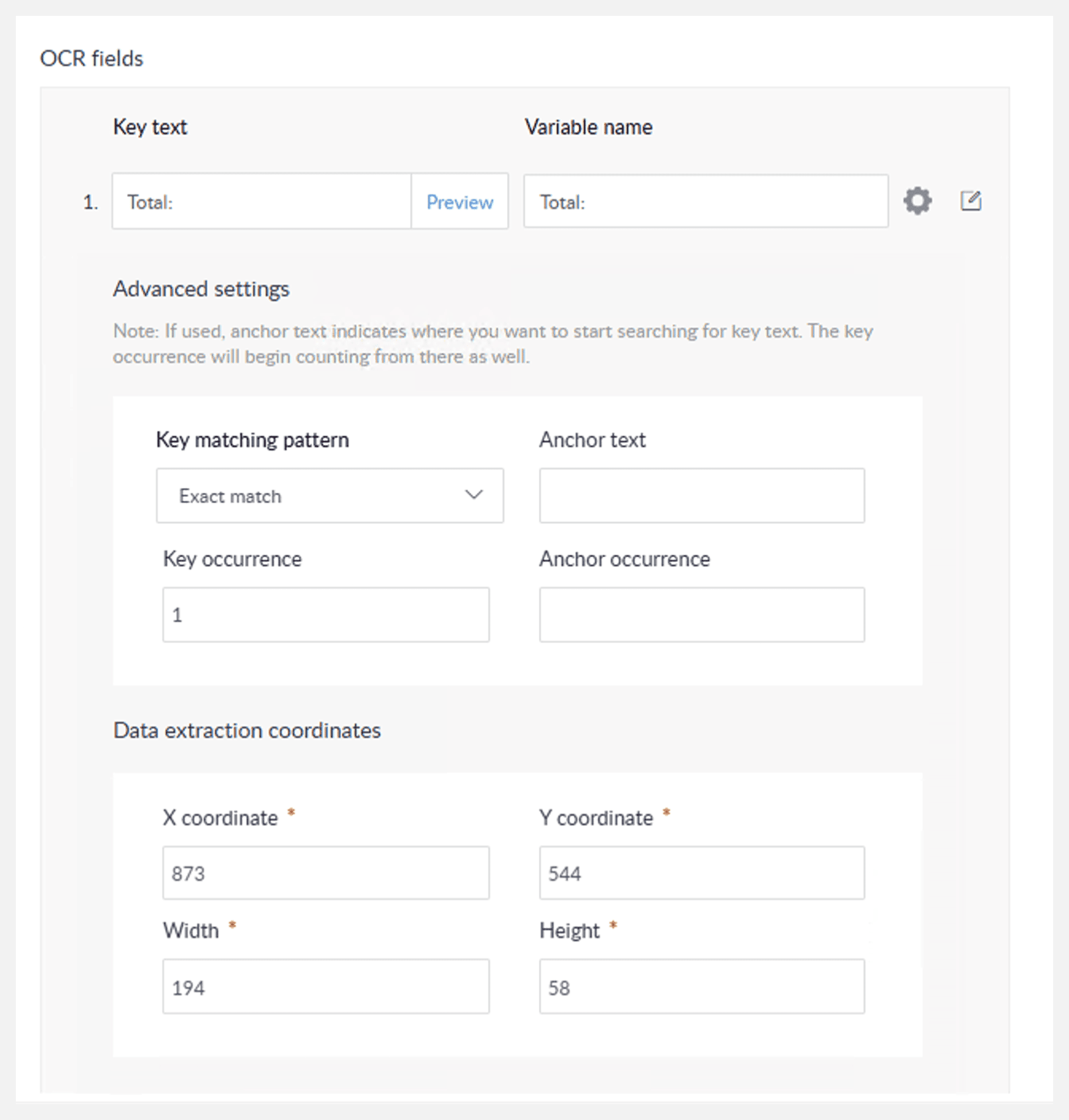
キーの出現回数:キー文字列が複数回出現する場合に、どの出現箇所を使用するかを指定します(例: 1 は 1 回目、2 は 2 回目)。
アンカーテキスト: 画像内でキー文字列の位置を特定するために使用するテキストです。キーが複数回出現したり、位置が変動する場合に利用します。ボットが画像全体を検索するのではなく、このアンカーテキスト付近からキー文字列の検索を開始するための基準点となります。
たとえば、請求先住所を抽出したいが、同じ住所が「Billing Information」と「Shipping Information」の 2 か所に表示されているとします。この場合、「Billing Information」をアンカーテキストとして指定することで、最初の請求先住所のみを抽出できます。
アンカーの出現回数:抽出を開始する前に、アンカーテキストが何回出現するかを指定します。
データ抽出座標: キーに対する相対位置として、抽出したいデータの位置とサイズをピクセル単位で指定します(X(横方向)、Y(縦方向)、抽出領域の幅と高さ)。
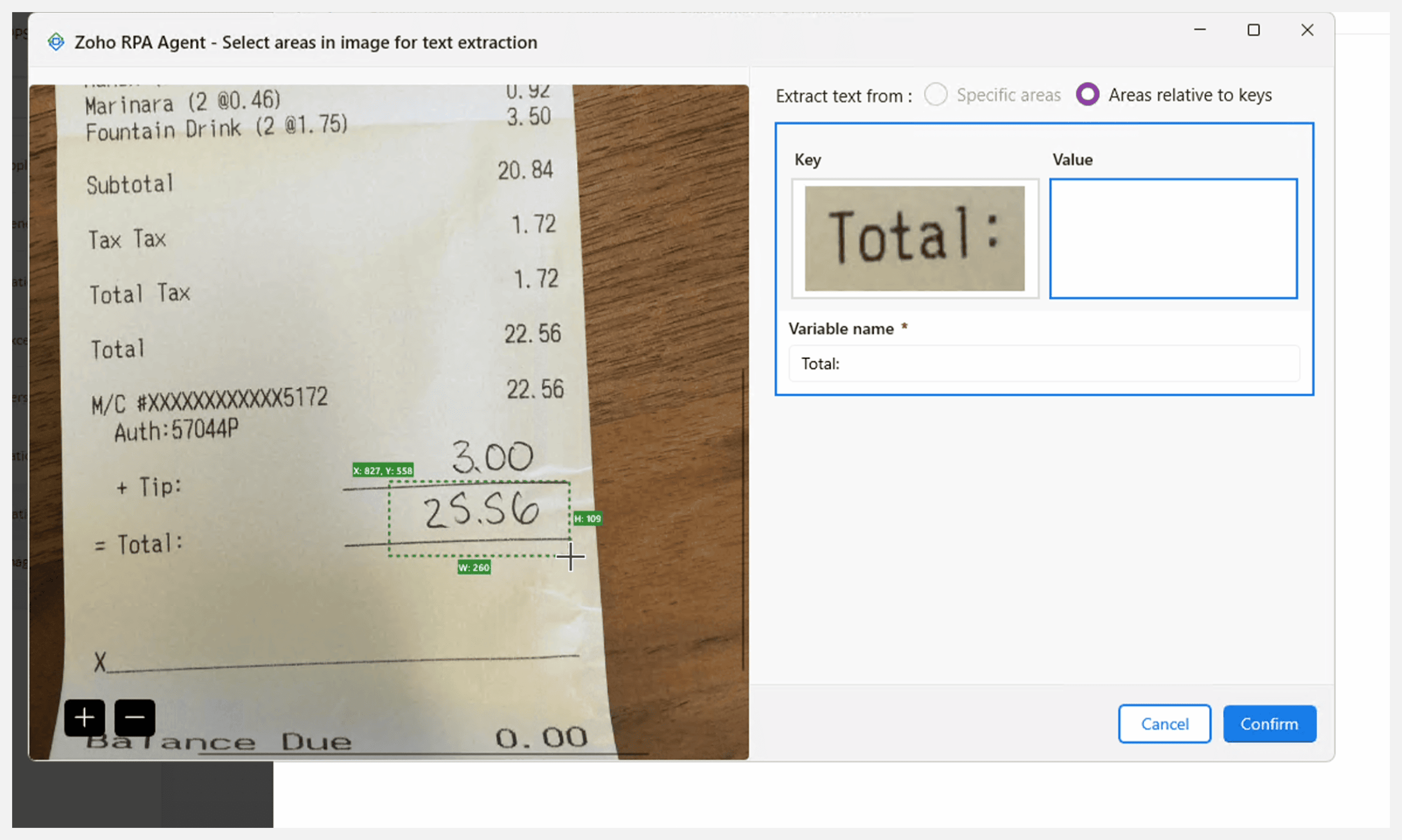
X: 画像の左端から、抽出したいデータ領域の左上までの水平方向の距離(ピクセル)です。
Y: 画像の下端から、抽出したいデータ領域の左上までの垂直方向の距離(ピクセル)です。

幅: X 座標から測った、抽出したいデータ領域の水平方向のサイズ(ピクセル)です。
高さ: Y 座標から測った、抽出したいデータ領域の垂直方向のサイズ(ピクセル)です。
メモ:
対応している画像形式は .jpg、.jpeg、.gif、.tif、.tiff、.png、.bmp です。
遅延設定
遅延設定を使用すると、アクションの前後に待機時間を挿入できます。これにより、ファイルのダウンロードなどの必要な処理が完了するまでボットを待機させてから、次のステップに進めることができます。
アクション前の遅延(ミリ秒): 現在のアクションを実行する前に、ボットが待機する時間(ミリ秒)を指定します。必要な要素やファイルがすぐに利用できない場合のエラー防止に役立ちます。
アクション後の遅延(ミリ秒): 現在のアクション完了後に、ボットが待機する時間(ミリ秒)を指定します。システムの更新や状態の安定化を待ってから、次のステップに進めたい場合に有効です。