
お知らせ:当社は、お客様により充実したサポート情報を迅速に提供するため、本ページのコンテンツは機械翻訳を用いて日本語に翻訳しています。正確かつ最新のサポート情報をご覧いただくには、本内容の
英語版を参照してください。
増分データフェッチは、データ元から新規または更新済みファイルをインポートする際に使用される手法です。Zoho DataPrep では、以下のクラウドストレージサービスから増分データを詳細選択機能を使ってインポートできます。
-
Google Drive
-
Zoho WorkDrive
-
Amazon S3
-
Dropbox
-
箱
-
Microsoft OneDrive
-
SharePoint
インポートを開始するには
1. 既存のパイプラインを開くか、パイプラインを作成し、ホームページ、Pipelines タブ、または Workspaces タブから、データを追加オプションをクリックします。
 情報: できること または クリックインポートする data
情報: できること または クリックインポートする data アイコンをパイプラインビルダーの上部でクリックすると、複数のソースからデータをパイプラインに取り込むことができます。
アイコンをパイプラインビルダーの上部でクリックすると、複数のソースからデータをパイプラインに取り込むことができます。
2. 左側のペインからCloud storageカテゴリーを選択し、必要なcloud storage サービスをクリックします。また、検索ボックスでcloud storage サービスを検索することもできます。
 メモ: 以前に接続を追加済みの場合は、左側のペインからSaved 外部連携カテゴリーを選択し、インポートを続行してください。Saved 外部連携について詳しくは、こちらをクリックしてください。
メモ: 以前に接続を追加済みの場合は、左側のペインからSaved 外部連携カテゴリーを選択し、インポートを続行してください。Saved 外部連携について詳しくは、こちらをクリックしてください。
3. 追加済みの接続がある場合は、既存の接続をクリックしてデータのインポートを開始します。
メモ: 新しく追加するリンクをクリックして新しい勘定を追加します。必要に応じて外部連携をいくつでも作成できます。
4. クラウドストレージアカウントを認証します。初めてこの操作を行う場合は、ファイルにアクセスするためにDataPrepの認証が必要です。
情報: Zoho WorkDriveの場合、データはZoho DataPrepにログインしている認証情報を使用して、WorkDriveアカウントから直接取得されます。
メモ: 接続設定は、今後クラウドストレージからデータをインポートする際に保存されます。認証情報は安全に暗号化され、保存されます。
詳細選択でインクリメンタルデータをインポート
5. データを増分インポートするには、詳細 selectionリンクをクリックします。
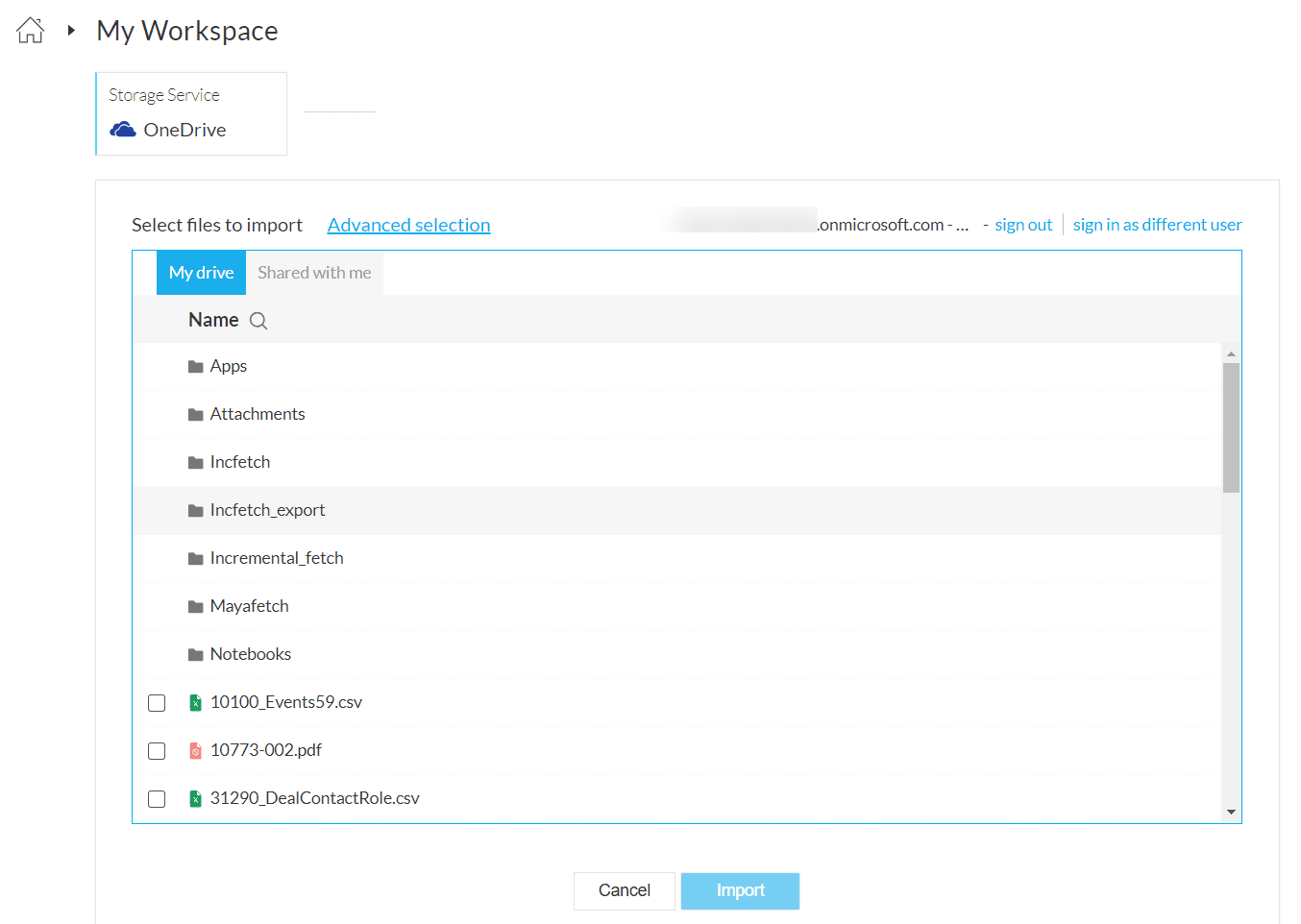 詳細 selectionを利用すると、正規表現を使った動的なファイル選択が可能です。新規または更新済みデータをクラウドストレージアカウントから取得する際に活用できます。ファイルパターンに一致するデータファイルがクラウドストレージサービスから取得されます。
詳細 selectionを利用すると、正規表現を使った動的なファイル選択が可能です。新規または更新済みデータをクラウドストレージアカウントから取得する際に活用できます。ファイルパターンに一致するデータファイルがクラウドストレージサービスから取得されます。
各利用可能なクラウドストレージサービスでの詳細 selectionオプションの使い方については、以下のリンクをご参照ください。
情報:クラウドストレージからの増分取得には、CSV、TSV、JSON、XML、TXTファイル形式のみサポートしています。
6. データのインポートが完了すると、Visual Pipeline builderが開き、トランスフォームの適用を開始できます。ステージを右クリックしてデータの準備オプションを選択し、DataPrep Studioページでデータの準備を行うことも可能です。こちらをクリックして、トランスフォームの詳細をご確認ください。
7. データフローの作成および各ステージで必要なトランスフォームの適用が完了したら、ステージを右クリックして宛先を追加し、データフローを完了してください。
8. パイプラインに宛先を追加した後、まず手動実行でパイプラインの動作を確認してください。手動実行が正常に動作することを確認したら、スケジュールを設定してパイプラインを自動化できます。実行方法の種類についてはこちらをご参照ください。
スケジュール、バックフィル、手動更新、Webhook、またはZoho Flowを設定する際は、すべてのデータ元に対してインポート設定が必須となります。インポート設定を行わない場合、実行内容を保存できません。こちらをクリックして、インポート設定方法の詳細をご確認ください。
9. 実行を設定した後、指定した時刻にパイプラインジョブが作成されます。ジョブのステータスや詳細は、ジョブ概要で確認できます。こちらをクリックして、ジョブ概要の詳細をご確認ください。
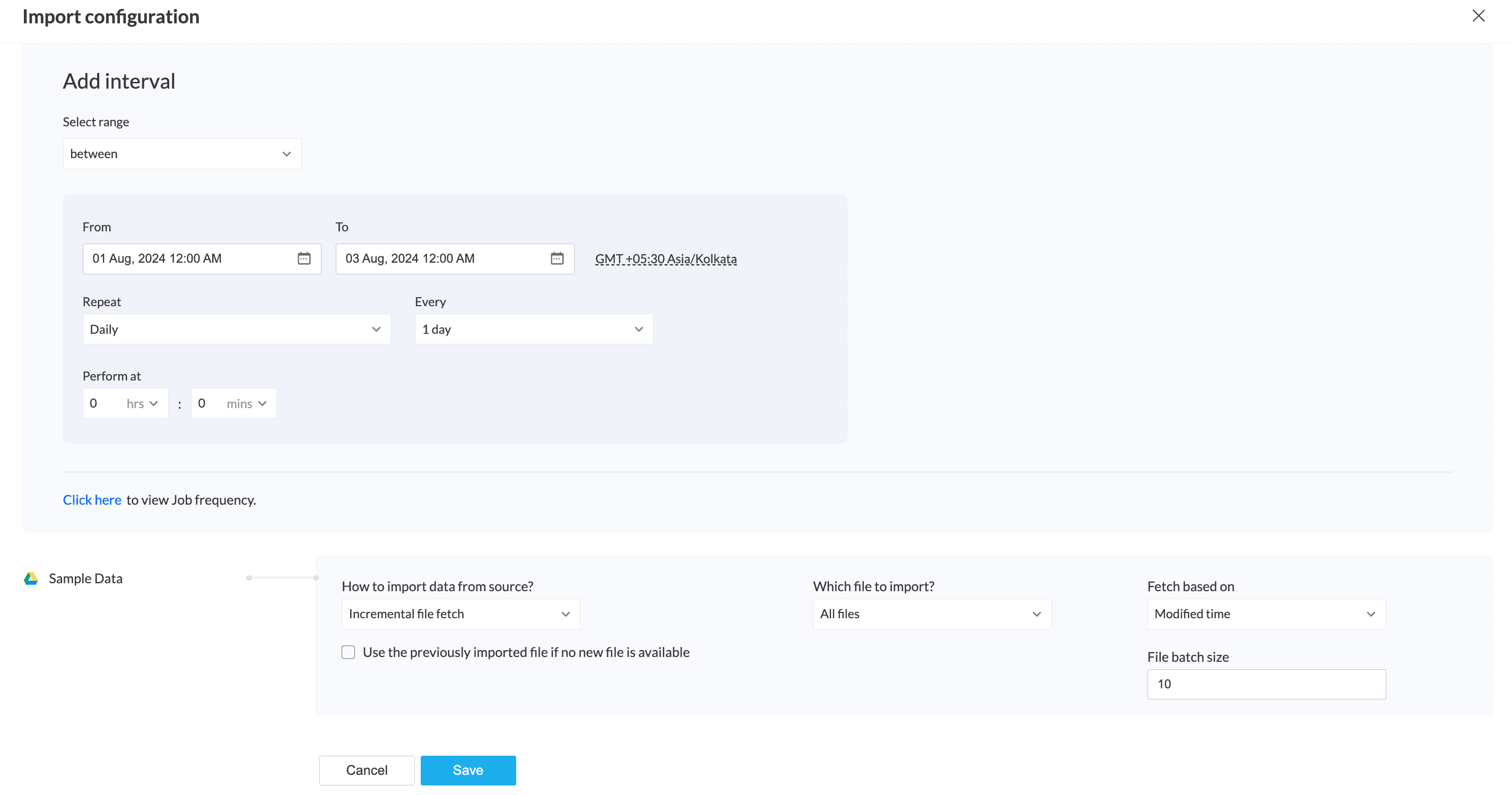
詳細選択のインポート設定
クラウドストレージからデータを詳細選択でインポートする場合、下記のインポート設定を使って、クラウドストレージからのインポート方法や増分データの取得方法を設定できます。
インポート設定を行うには、こちらをクリックのリンクを選択してください。
下記はスケジュール設定画面のスナップショットです。
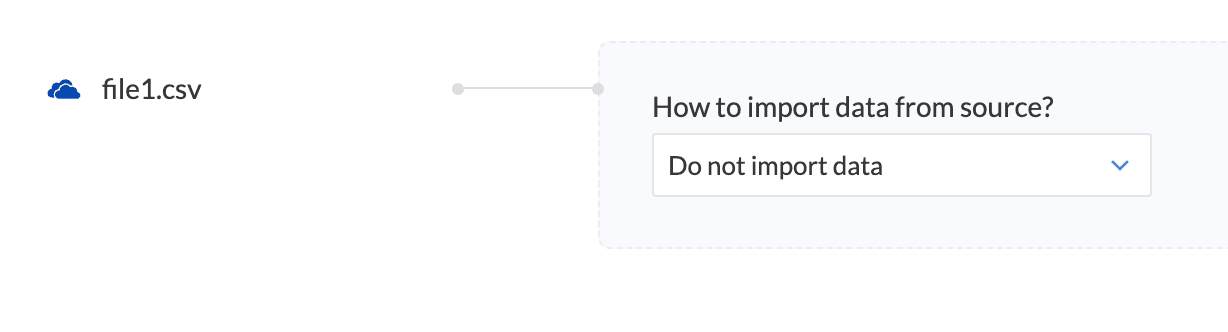
データ元からデータをインポートする方法
ドロップダウンからデータをインポートする方法を選択してください - すべてのデータをインポート、増分ファイル取得、データをインポートしない。
すべてのデータをインポート
このオプションは、ファイルパターンに一致するすべての利用可能なデータをインポートします。

ファイルバッチサイズ: すべてのファイルをインポートする場合、バッチサイズを指定します。ファイルは最初の更新時刻に基づき、この数値ごとにグループ化されます。グループ化されたファイルは1つのファイルとしてインポートされ、頻度に従って宛先へエクスポートされます。
情報:ファイルバッチサイズは10を超える値には設定できません。このオプションはクラウドストレージで詳細選択を行う場合のみ利用可能です。
増分ファイル取得
クラウドストレージから増分データをインポートおよび取得する方法を、インポートする設定オプションで設定できます。増分データインポートは、データ元から新規または更新済みのデータをインポートするための手法です。

新しいデータが利用できない場合、以前インポートしたデータを使用する:
- チェックボックスがオンの場合:データ元に新規データがない場合、最後に取得したデータを再度インポートします。
- チェックボックスがオフの場合:データ元に新規データがない場合、インポート処理は失敗し、ファイルはインポートされません。その結果、パイプラインジョブ全体が失敗します。
どのファイルをインポートするか?インポートするファイルとしてすべてのファイル、最新ファイル、または最古ファイルをこのオプションで選択できます。
すべてのファイル
このオプションを選択すると、指定したファイルパターンと一致するすべてのファイルが、特定のデータ間隔内でFetch based オン項目に基づきインポートされます。
Fetch based オン:ファイルを並べ替えてインポートする際に基準となる時間を選択できます - 更新済み時間、作成時間。
メモ:Google Drive、OneDrive、SharePoint、箱には、modifiedTimeとcreatedTimeが存在します。
DropBox、Amazon S3にはmodifiedTimeのみがあり(作成時間はありません)
File バッチ size:すべてのファイルを段階的にインポートする場合のバッチサイズを指定します。ファイルは、この番号でグループ化され、指定したデータ間隔内で最初に作成または更新された時間を基準にまとめられます。グループ化されたファイルは1つのファイルとしてインポートされ、指定された頻度でエクスポートされます。
Info:File バッチ sizeは10を超える値に設定できません。このオプションは、クラウドストレージの詳細選択時のみ利用可能です。
Newest file
このオプションを選択すると、指定したファイルパターンに一致し、指定したデータ間隔内でFetch based オンで指定した項目に基づき、最新のファイルがインポートされます。

Oldest file
このオプションを使用すると、特定のデータ間隔で指定したファイルパターンに一致する最も古いファイルが、Fetch based オン項目に基づいてインポートされます。

データをインポートしない
データは一度だけインポートされます。2回目以降は、同じデータにルールが適用され、エクスポートされます。
インクリメンタル同期の仕組み
インポート設定オプションを使用して、データ元からインクリメンタルデータをどのようにインポートおよび取得するかを設定できます。インクリメンタルデータインポートは、新規または更新済みデータを特定のデータ間隔でインポートする方法です。
インクリメンタルファイル取得では、パイプライン実行時に新規または更新済みファイルが取得されます。各データ間隔ごとに、前回の間隔以降に作成または更新されたファイルがインポートされます。クラウドストレージに新しいファイルがない場合はデータがインポートされず、またはインポート設定に従って以前インポートしたデータが再度取得されます。次のデータ間隔では、その間隔内で作成または更新されたファイルが取得され、この処理が繰り返されます。
スケジュール実行でのインクリメンタル取得
インクリメンタルファイル取得では、パイプラインがスケジュールされた際、最初のスケジュールのデータ区間は前へから現在のデータ区間までとなります。この期間中に、すべての新規または更新済みファイルが取得されます。2回目のスケジュールでは、現在の区間から次の区間へと延長され、その後のスケジュールも同様のパターンで進行します。
例として、スケジュールが1時間間隔に設定されている場合、データ元には合計10ファイルがあり、そのうち5ファイルは1時間前にアップロードされ、ファイルパターンに照合します。インポートする設定はすべてのファイルをインクリメンタルにインポートするように設定され、バッチサイズは10に設定されています。

最初のスケジュールが実行されると、直近1時間以内に作成または更新された5ファイルが取得され、1つのファイルとしてエクスポートされます。
2回目のスケジュールでは、同じファイルパターンに合致する新規ファイルが4件データ元に追加された場合、その4ファイルのみが取得され、該当区間の作成または更新時間に基づき1つのファイルとしてエクスポートされます。
3回目のスケジュールで、ファイルパターンに照合する新規ファイルが13件データ元に追加された場合、バッチサイズが10に設定されているため、最初の10ファイルのみが取得され、作成または更新時間に基づき1つのファイルとしてエクスポートされます。同じロジックが、以降のスケジュールにおけるインクリメンタル取得にも適用されます。
こちらをクリックしてスケジュール実行について詳しくご覧ください。
バックフィル実行時のインクリメンタル取得
インクリメンタルファイル取得において、パイプラインにバックフィル実行が設定されている場合、指定されたデータ区間内のすべてのインクリメンタルファイルが取得されます。
例えば、バックフィルが8月1日から3日まで毎日ジョブ頻度で設定されている場合、8月1日には4ファイル、8月2日には7ファイル、8月3日には13ファイルがあります。インポートする設定は、すべてのファイルをインクリメンタルに取得し、バッチサイズは10となっています。
最初のバックフィルジョブでは、8月1日に作成または更新済みの4件のファイルが取得およびエクスポートされ、1つのファイルとしてまとめられます。2回目のバックフィルジョブでは、8月2日の7件のファイルも同様に処理され、エクスポートされます。3回目のバックフィルジョブでは、8月3日の最初の10件のファイルが取得およびエクスポートされ、1つのファイルになります。
こちらをクリックしてバックフィル実行についてご確認ください。
更新データのインクリメンタル取得
インクリメンタルファイル取得では、パイプラインに更新するが設定されている場合、指定したデータ期間内のすべての新規または更新済みファイルが取得されます。
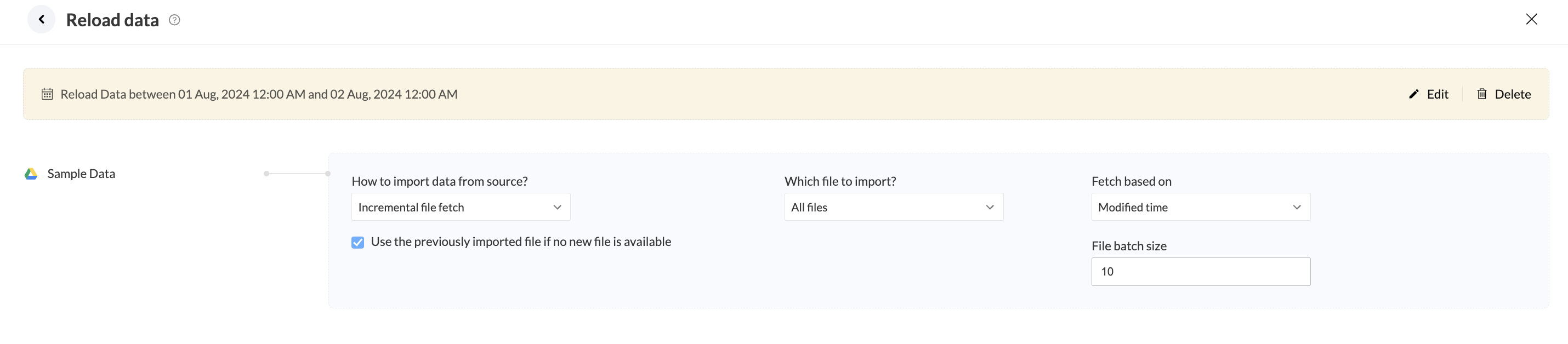
例えば、更新するが8月1日から2日の間に設定されています。
8月1日は3件、8月2日は4件のファイルがあります。インポートする設定では、最も古い作成時間を基準にバッチサイズ5で全ファイルをインクリメンタルに取得するようにしています。
更新するジョブの際、8月1日に作成された3件のファイルと、8月2日に作成された最初の2件のファイルが取得およびエクスポートされ、1つのファイルとなります。
こちらをクリックして更新するについてご確認ください。
関連情報