DataPrep 2.0の新機能とは?

DataPrep 2。+10、-10のリリースを発表できることを大変嬉しく思います。新規バージョンでは、エンドツーエンドのパイプラインを簡単に作成でき、データ品質の管理やデータ移動のコントロールも自在です。DataPrep 2。+10、-10は、複数のデータソースや宛先間でのデータ統合も強化され、ETLプロセス全体の効率がさらに向上します。DataPrep 2。+10、-10の新機能についてご紹介します。

Zoho DataPrep 2.0の新機能
エンタープライズや小規模組織の双方に対応し、トレーニングや学習コストを最小限に抑えつつ、複雑なユースケースからシンプルな利用まで幅広くカバーする完全なデータパイプラインプラットフォームの開発に注力しました。
これらの価値観をもとに、Zoho DataPrepの新規メジャーアップデートでは、以下の5つの重点分野に取り組みました。
- 基本機能の強化と複雑さの簡素化
- プラットフォームの拡張性
- モニタリングおよびリネージュ
- ユーザーエクスペリエンスの向上
データパイプラインの基礎
Zoho DataPrep の基本機能を強化することは、進化し続ける顧客ニーズへの対応を目的としています。Zoho DataPrep は、高度な変換エンジンを搭載し、数十億行規模までスケールできる堅牢な基盤を持っています。250種類以上の組み込み変換をコーディング不要で、ポイント&クリックのインターフェースからすべて操作できます。
Zoho DataPrep における詳細なデータ準備
2。+10、-10 では、Zoho DataPrep 内でデータ準備の実行、オーケストレーション、運用方法に対してメジャーアップデートが導入されました。
データパイプライン全体を単一の項目として管理できるようになり、これまでのように各準備段階を個別のデータセットとして扱う必要がなくなりました。
インポートする、処理、エクスポートするを一つのスケジュールプロセスで実行できるため、それぞれを個別に順序設定したり、スケジュール時間を手動で調整したりする必要がありません。
インクリメンタルフェッチシナリオでのデータ取得済みは、前回のインポートではなく、2。+10、-10 のスケジュール間隔に基づいて行われます。これによりデータ移動のプロセスが簡素化され、失敗したジョブの再開も容易になります。
Zoho DataPrep 2.0 では、上記すべての変更点およびその他の内容が、以下の機能によって提供されます。
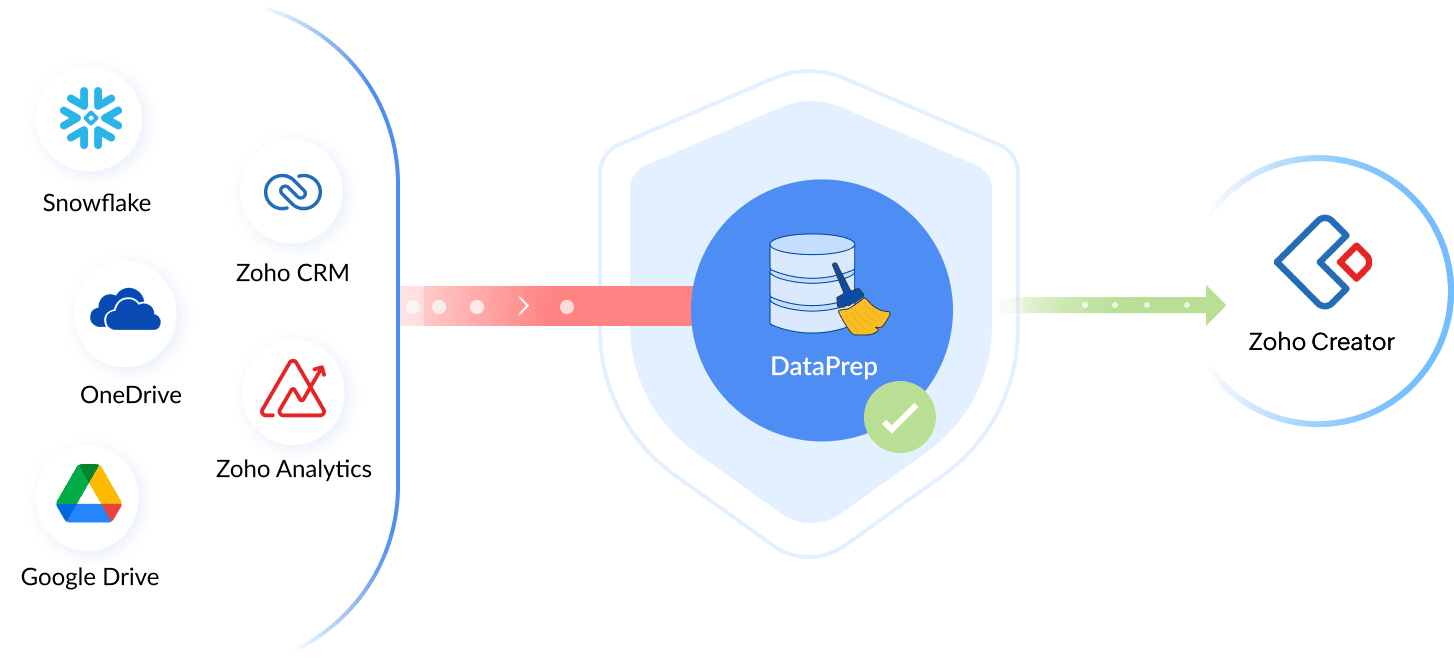
ビジュアルパイプラインビルダー
すべて-新規 パイプラインキャンバスにより、エンドツーエンドのデータフローをシームレスに設計できます。従来は一度に単一のデータセットしか扱えませんでしたが、2。+10、-10では、複数のソースからデータを取得し、1つ以上のデータセットを同時に準備・使用できるようになり、データを複数の宛先にエクスポートすることも可能です。これにより、ビジネスデータの可視化が向上し、複雑なワークフローやデータ統合が簡素化され、より自信を持ってデータを扱えます。詳細はこちら

詳細スケジューリング
DataPrep 1。+10、-10 では、データソースとデータ出力先ごとに個別にスケジュールを設定する必要があり、スケジュールの時間をずらして手動で管理しなければならず、手間がかかっていました。しかし、2。+10、-10 では、スケジューリングがパイプライン単位で行えるようになりました。1つのスケジュールで、パイプライン内のすべてのソースと出力先に対するインポート、処理、エクスポートをまとめて管理できます。詳細はこちら
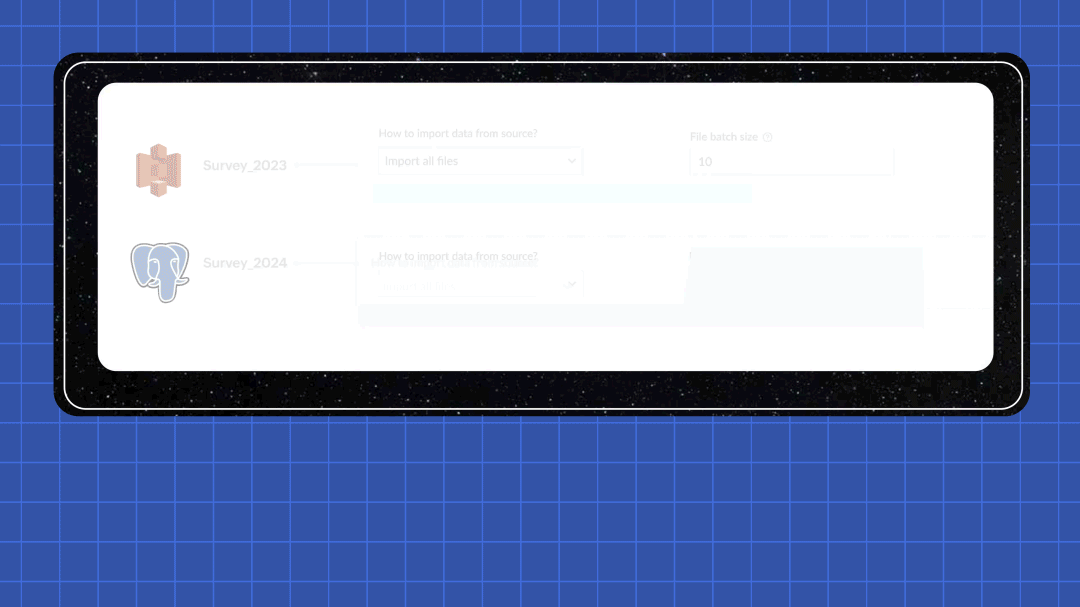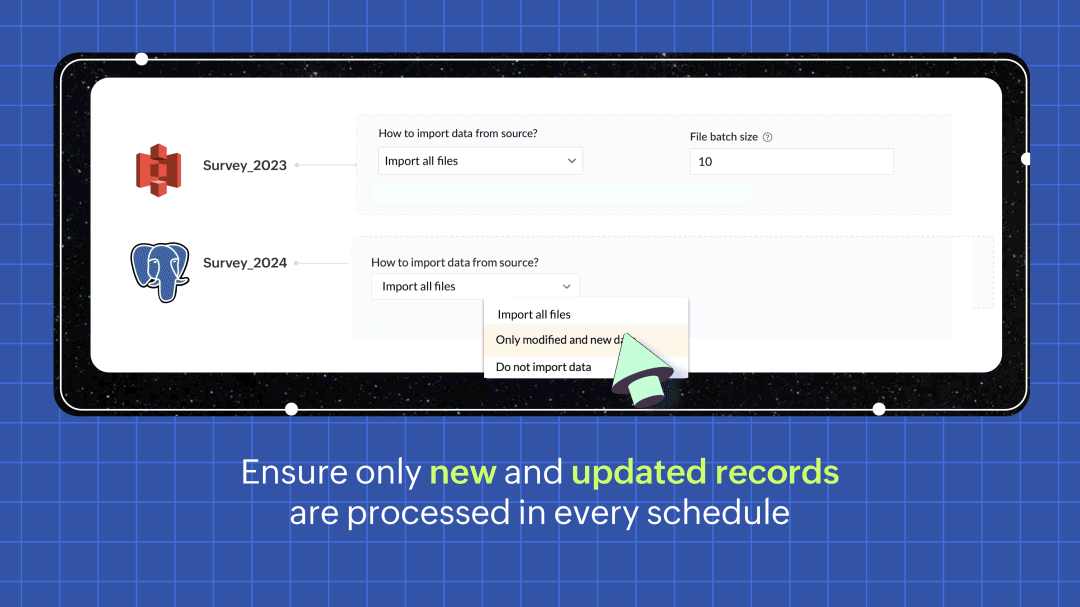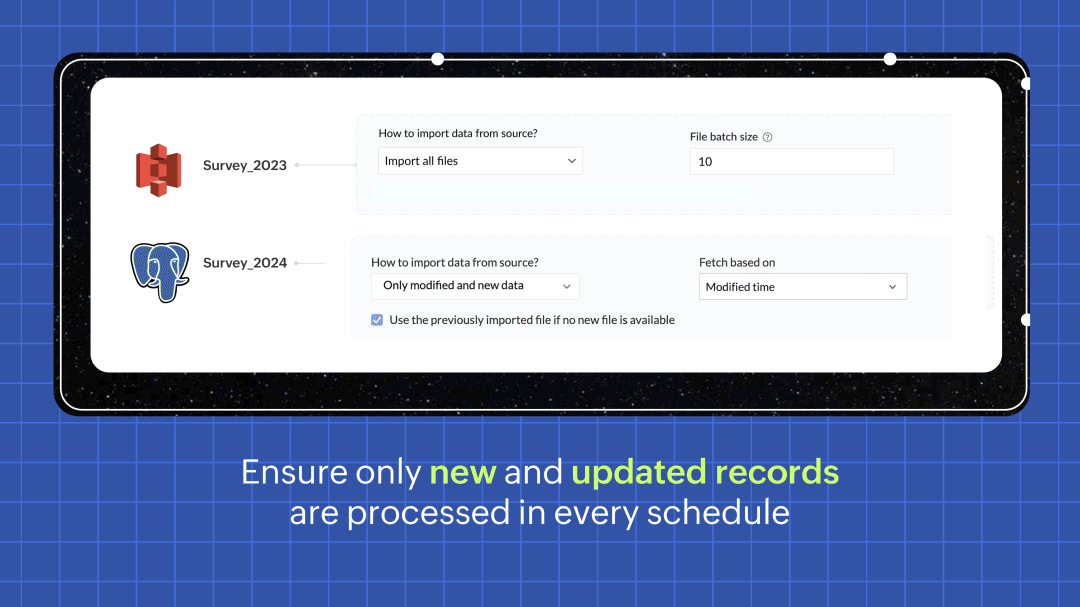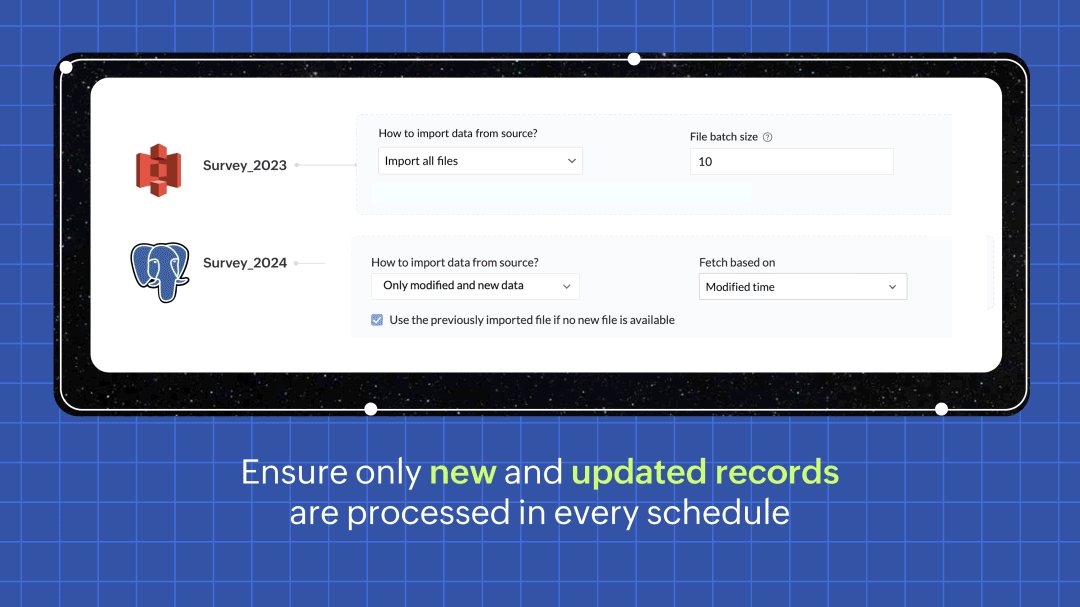
すべてのSourcesに対応したインクリメンタルフェッチ
頻度パイプライン実行時にインクリメンタルフェッチオプションを選択すると、データ元の新規および更新されたデータのみが取得され、DataPrepに送信されて処理されます。これにより、新しく追加された行だけが処理されるため、各インクリメンタルフェッチの実行が従来よりも高速になります。作業効率が向上し、コスト面でも効果的です。詳細はこちら
データバックフィル
データモデルやデータ準備ワークフローの変更により、前へスケジュールで処理されなかったデータを処理できます。特にファイルベースのデータパイプラインの場合でも、すべてのデータ処理を一つずつ実行することなく対応可能です。 詳細はこちら
Reusable Pipeline テンプレート
作成したData pipelineを、pipelineテンプレートとして保存できるようになりました。これにより、データパイプラインの再利用や複製が簡単に行えます。詳細はこちら
テンプレートのギャラリー
データの準備やクレンジングに関するさまざまな使用するケースに対応する、事前構築されたテンプレート付きのパイプラインやルールセットをギャラリーにて出版しています。ユーザーはこれらの事前構築済みテンプレートを活用し、データ準備の作業をすぐに開始できます。詳細はこちら

マクロ
選択済みのルールのみをテンプレートとして保存できるようになりました。ルールセット全体を保存する必要はありません。また、特定の機能を持つマクロを保存する柔軟性も追加されました。
拡張されたコネクターサポート
自動データパイプラインを作成するためには、プラットフォームが多様なソースおよびデスティネーションに接続できる能力が不可欠です。これを踏まえ、Zoho DataPrepに多数のコネクターを追加します。Zoho Creatorコネクターの追加に続き、DataPrep 2のGAリリース(+10、-10バージョン)で提供予定のコネクターは以下の通りです。
- DataPrep用 Salesforce コネクター
- DataPrep用 Zoho Bigin コネクター
- DataPrep用 Zoho Forms コネクター
レジリエンスの強化
データパイプラインは同期処理中に失敗する可能性がありますが、高いレジリエンスが求められます。Zoho DataPrepでは、処理基盤およびデータソースやデータ送信先へのインポートする・エクスポートする処理において、自動リトライ機能を導入し、データパイプラインの堅牢性を大幅に向上させました。
5倍のパフォーマンス向上
プラットフォームのパフォーマンス能力が5倍に強化されました。これは、DataPrepが現在1回のバッチで処理できるデータの金額に明確に表れています。2021年に商品 戻るをリリースした際は、1バッチあたり100万行の処理能力でしたが、すぐに500万行まで拡張しました。
2。+10、-10 バージョンでは、箱からのバッチ出力で最大2,500万行までサポートできるようになりました。さらに、特別なデプロイメントを完了 オンリクエストで最大1億行までスケールアップ可能です。
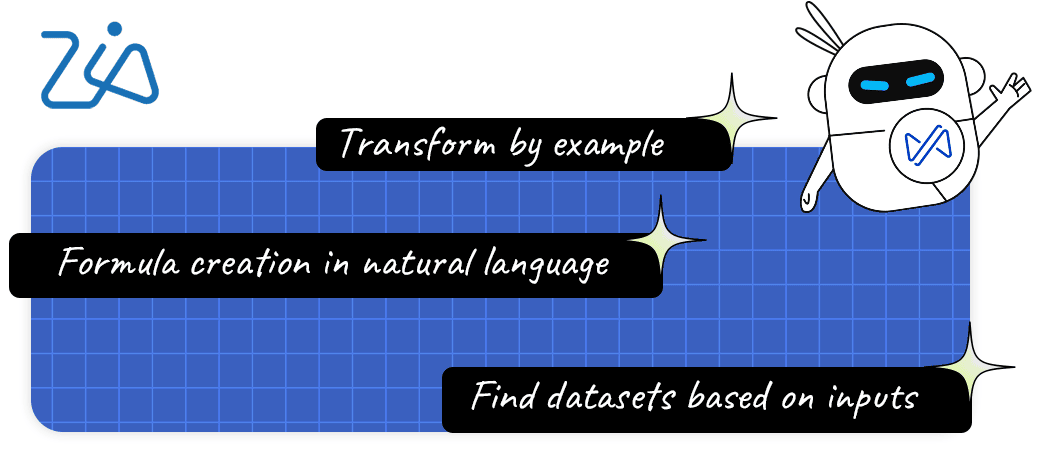
新規 AI搭載トランスフォーム
DataPrepはOpenAIのChatGPT APIと連携し、より高度なデータ変換やデータの強化が可能になりました。今回の連携により、例による変換、数式ジェネレーター、データセットファインダーなどの新機能を利用できます。
自動スキーマ検証
データをデータ送信先にプッシュする際、データモデルの不一致によりエクスポートするが一部失敗し、データエクスポートの再開やデータ整合性の維持が困難になる場合があります。これを防ぐため、データの種類 サポートがあるすべての送信先(データベースやアプリケーションなど)に対し、スキーマ検証を自動で実行します。
モニタリングとリネージ
Zoho DataPrepプラットフォームの可観測性が、新規のモニタリングおよび監査機能により大幅に向上しました。この分野でどのような改善が行われたのか、順にご紹介します。
Jobs 履歴と監査
頻度 pipeline execution がジョブとして追跡され、各ステージのステータスも個別に管理されるようになりました。各パイプラインにはジョブの一覧が表示され、手動実行、スケジュール実行、バックフィル実行など、実行方法ごとに分類されています。詳細はこちら
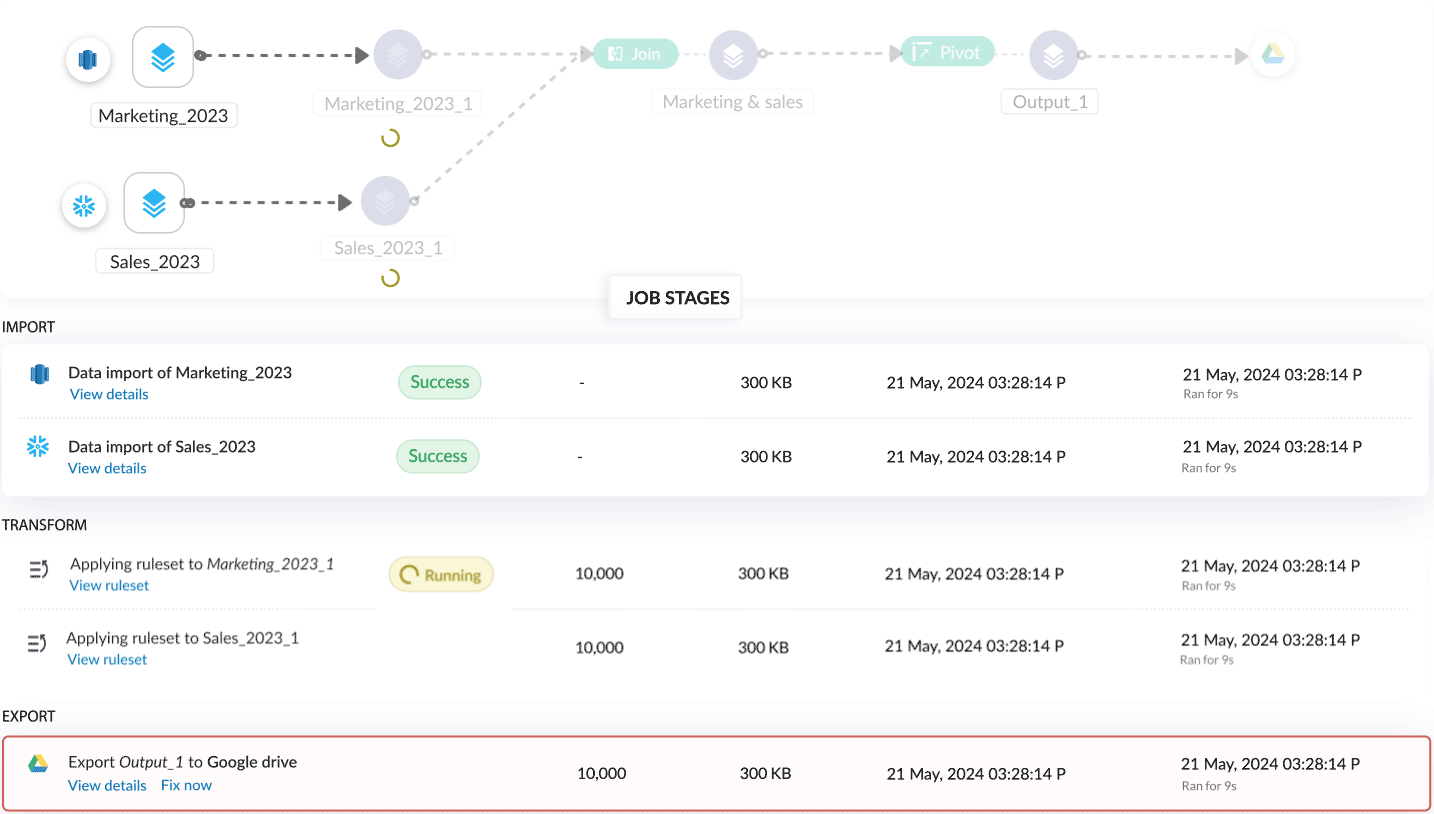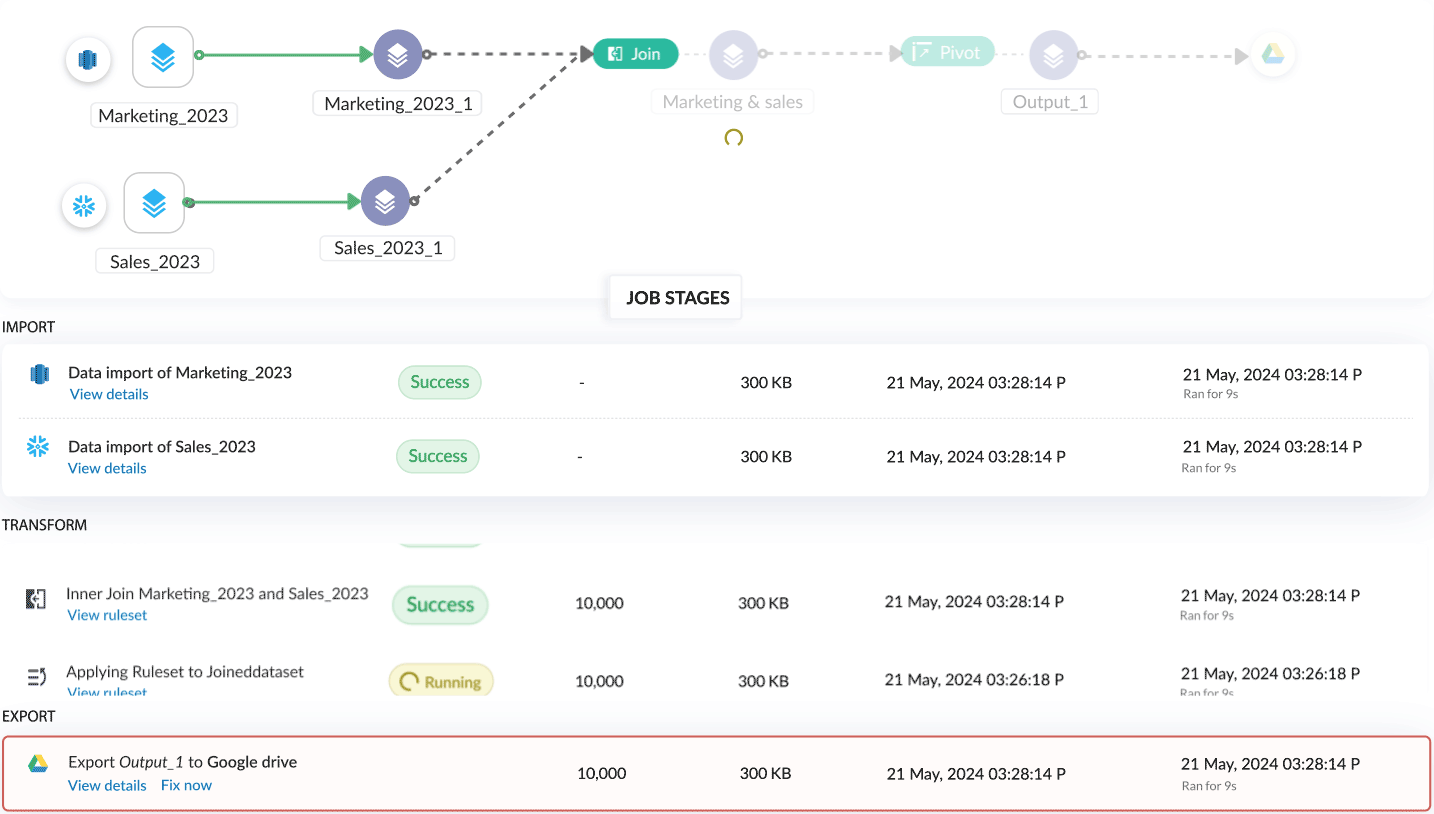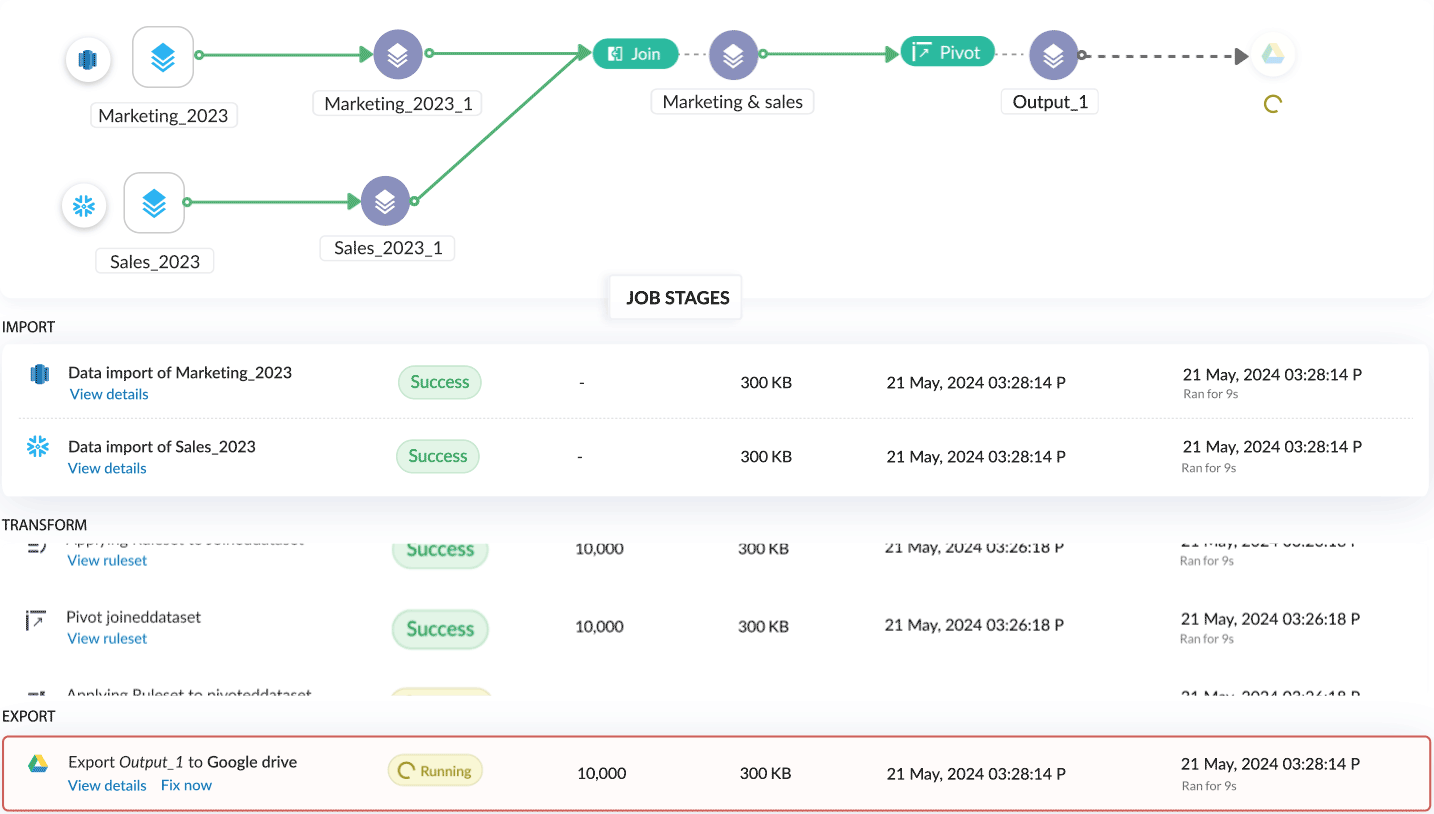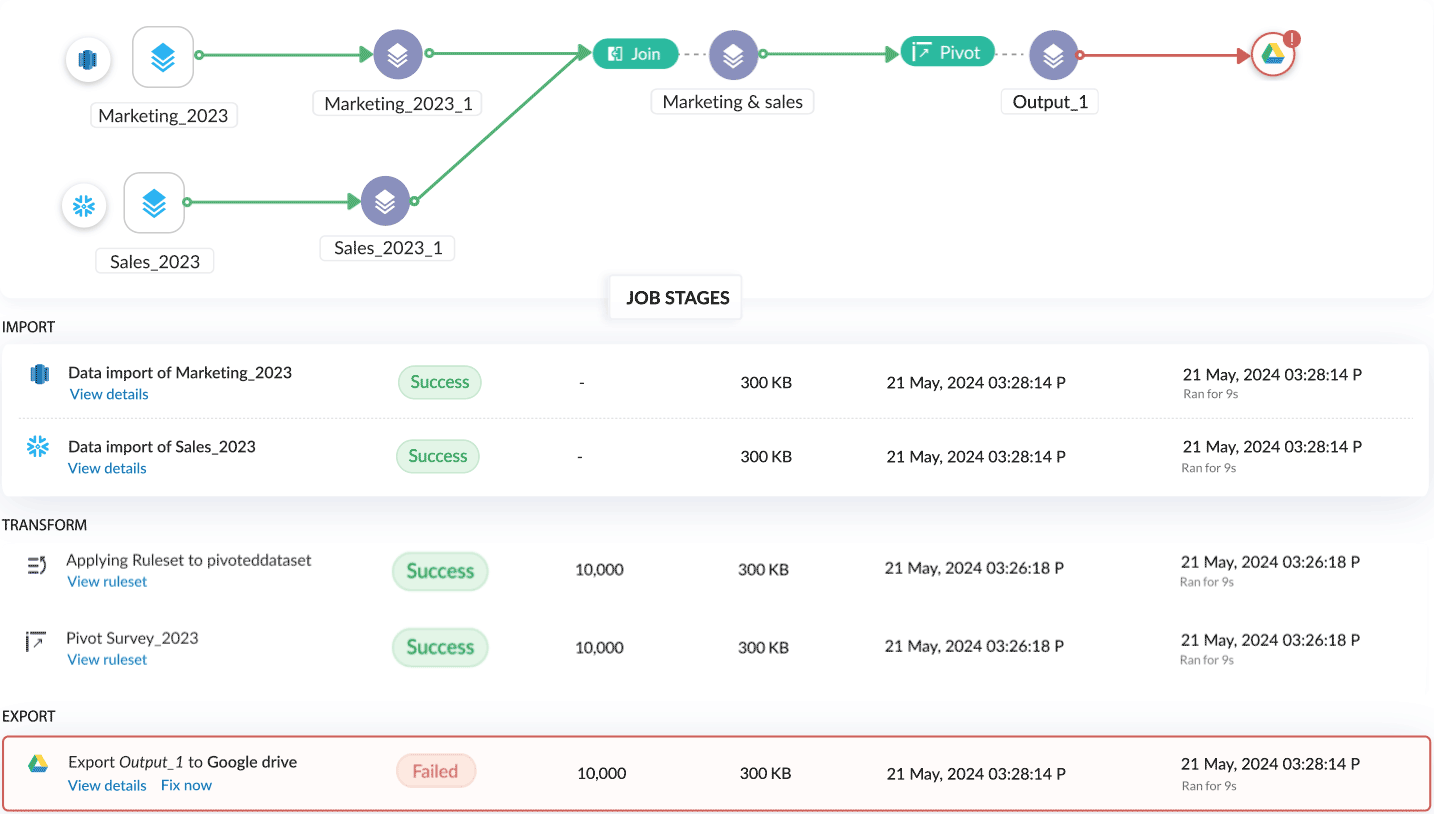
詳細デバッグ
各ジョブには3つのセクションがあり、最初のセクションでは各ステージのステータスを視覚的に表示し、パイプライン実行の概要として、処理済み行数、ストレージ、消費時間、特定ジョブのデータ区間など、全体の統計情報が確認できます。
2つ目のセクションでは、すべての処理ステージの一覧が表示され、各ステージごとに個別のステータスや、処理済み行数・消費時間などの詳細情報を確認できます。詳細はこちら
Monitoring ダッシュボード
Zoho DataPrep内のすべてのjobsを、新しいホームページであるMonitoringダッシュボードから監視できるようになりました。新しいダッシュボードでは、システム内で成功したデータパイプラインや失敗したデータパイプラインの情報を確認できます。詳細はこちら

組み込みバージョン管理
データパイプラインでのデータ準備中に行われたすべての変更は、バージョンとして記録・保存されます。いつでも任意のバージョンに移動し、そのバージョンにパイプラインを戻すことが可能です。つまり、データパイプラインのライフサイクル全体を通じて、無制限の取り消し・やり直し機能を利用できます。詳細はこちら
ステージング環境と本番環境
パイプラインを操作する際、あるマイルストーンに到達し、パイプラインのスケジュール準備が整った段階で、「ready」に設定できます。「ready」に設定されたパイプラインバージョンは有効バージョンとなります。以降の変更は下書きバージョンとして管理され、スケジュール済みジョブには影響しません。変更が完了したら、再度パイプラインを「ready」に設定することで、スケジュール済みジョブに変更が反映されます。この仕組みにより、本番パイプラインに影響を与えることなく、データのテストや検証を継続できます。詳細はこちら
Access & 活動監査トラッキング
組織のデータが複数のステークホルダーにアクセス可能な場合、誰がどのデータにアクセスしたかを把握することが重要です。この機能により、Zoho DataPrep 内でどのユーザーがどのデータワークフローにアクセスしたかを監視でき、アクセスおよび活動の監査ログによってデータのセキュリティと責任追跡を強化します。詳細はこちら
プラットフォーム拡張性
さまざまなデータソースやデータの出力先とのシームレスな連携は、効率的なデータ準備ソリューションにとって不可欠です。ヘルプ組織が進化し続ける法人のニーズに合わせて柔軟にデータソリューションを構築できるよう、プラットフォームの機能を拡張しました。
ワークフローによる業務の自動化 with Zoho Flow
Zoho Flowとの強力な連携により、Zoho DataPrepをさまざまな他のソフトウェアやソリューションと接続し、コード不要でデータワークフローを自動化できます。シンプルな連携により、Zoho Flow上でデータパイプラインを簡単にオーケストレーション可能です。Zoho Flow内でデータパイプラインを操作として実行できるほか、job完了、job failure、job completionなど、DataPrepのトリガーを使ってフローの開始も選択できます。
Whitelabel DataPrep
Zoho DataPrep を完全にリブランディングした独自のバージョンで、データサービスを効果的に強化できます。DataPrep のホワイトラベル機能により、プロフェッショナルなデータサービスを低コストで提供可能です。IT 専門家やデータアナリストがいなくても、簡単にデータの抽出や準備が行えます。
REST API
統合をより迅速に作成できるよう、Zoho DataPrep の REST API エンドポイントを公開します。まもなくすべてのユーザーが利用可能となります。これにより、Zoho DataPrep 内で構築したデータパイプラインを、他のアプリケーションやプロセスと統合した REST API を通じてオーケストレーションできます。API を利用することで、データパイプラインの開始や停止、ジョブのステータス情報の取得などの操作が可能です。
その他の更新情報
リアルタイムData品質モニター
データセット詳細パネルを開かずに、データ品質をモニターできるようになりました。DataPrep Studioページの上部に常にデータ品質が表示され、データへの変更があるたびに最新の情報に更新されます。
列エクスプローラー
100列を超えるデータセットを扱う際、必要な列を探したり、作業したい列に移動したりするのが難しいことがあります。列エクスプローラーを使えば、簡単に列を検索でき、データ品質でフィルターすることも可能です。そのため、まずデータ品質に問題のある列に対応できます。また、不要な列を一時的にStudioページ上で非表示にし、データ準備中に重要な列だけに集中することもできます。 詳細はこちら
ルールセットでの一括処理
ルールセットに対して一括処理が可能になり、複数のルールを同時に選択して削除・無効化・有効化できます。また、すべての適用済みルールをクリアして、最初からやり直すこともできます。 詳細はこちら
Ruleset テンプレートのファイルとしてのエクスポート
ruleset テンプレートを項目として保存し、DataPrep 組織内で共有するだけでなく、ruleset をファイルとしてエクスポートできるようになりました。このファイルは、他の組織のユーザーとテンプレートを共有したり、クライアントへのプロフェッショナルサービスの提供、または外部のバージョン管理システムでのトラッキング用に保存したりする際に活用できます。詳細はこちら
マルチファイルバッチインポート
ファイルをシステムにインポートする際、複数のファイルを1つのデータセットとしてまとめることができるようになりました。ローカルファイルシステムやクラウドストレージからのファイルインポート時の詳細インポートフローでは、インポート時にファイルを結合するオプションが選択可能です。一度に最大10ファイルまで結合できます。詳細はこちら
アプリ向けターゲットマッチングの強化
ターゲットマッチングは、データベースだけでなくZoho DataPrepで利用可能なすべてのアプリケーション送信先にも対応するようになりました。これにより、ターゲットアプリケーションで求められるデータ型や制約を的確に管理でき、復旧が困難な部分的なエクスポートエラーの回避につながります。詳細はこちら
フィルターおよび並べ替えの強化
Zoho DataPrep のすべての変換に、フィルターおよび並べ替えパネルがタブとして追加されました。これにより、変換とフィルター・並べ替え機能を組み合わせて利用でき、これらの処理を個別に実行する手間が省けます。
ローカルファイルシステムからの自動ファイルインポート
ローカルマシンからファイルをインポートして有効なパイプラインを設定できるようになりました。クラウドやFTPシステムにデータをアップロードする必要はありません。Databridge を利用してローカルマシンとクラウド型 DataPrep サービスを連携し、ローカルマシン上のファイルを取得できます。S3やGoogle Driveなど他のクラウドストレージと同様に、増分取得機能にも対応しています。詳細はこちら
データソースおよびデータ出力先の管理の向上
データセットのデータ元を再インポートやデータフローの再作成をせずに変更できるようになりました。さらに、データのインポートやエクスポートフローに関する詳細設定や、データベースやアプリケーションの接続情報の変更も柔軟に行えます。
データおよびモデル変更の自動伝播
データパイプラインは複雑で、同じパイプライン内の異なる部分で変更を完了するために戻る・進むを繰り返す必要があります。パイプラインに多くの親子関係を設定すると、親データセットで加えたデータの変更が自動的に子データセットへ反映されない場合、非常に不便です。2。+10、-10では、データおよびモデルの変更が自動的にパイプライン内の子ステージに伝播されます。子ステージを開くときに変更が反映されるため、親データセットで作業中のパフォーマンスやスピードを維持しつつ、子データセットを開いた際に最新のデータやモデルを確認できます。
詳細な通知コントロール
新しく導入された通知設定により、どの通知を受領し、どの通知を表示しないかを制御できます。各通知ごとに、メール通知、製品内通知、両方、または受信しない、のいずれかを選択できます。詳細はこちら
共有機能の簡素化
新しいバージョンのDataPrepでの利用状況を分析したところ、多くのユーザーがdata-consumer-onlyユーザー役割を実際には使用していないことが判明し、一部のユーザーにとっては混乱を招いていました。ほとんどの共有は、データ準備フローを開発するためにパイプライン上で作業を行うユーザー間で行われていました。この調査結果をもとに、役割や権限を把握する手間なくデータパイプラインを共有できるよう、共有機能を簡素化しました。より詳細なユーザー向けには、独自のニーズに合わせて役割を作成できる機能も開発中です。詳細はこちら
個人データ監査の統合
個人情報および電子的保護対象医療情報(ePHI)のカラムがすべてのワークスペースでマークされ、管理者は設定画面からDataPrepデータパイプラインを通過するすべての個人データの概要を把握できるようになりました。このパネルから該当するパイプラインへアクセスし、個人情報や健康情報をマスキング、トークン化、または削除することで、効果的に管理・保護することが可能です。詳細はこちら