To export data to Zoho Analytics
1.
Open an existing pipeline or create a pipeline from the Home Page, Pipelines tab or Workspaces tab. You can bring your data from 50+sources.2. On the
Pipeline Builder page, once you have completed creating your data flow and applying the necessary
transforms in your stages, you can right-click a stage and select the
Add Destination option.
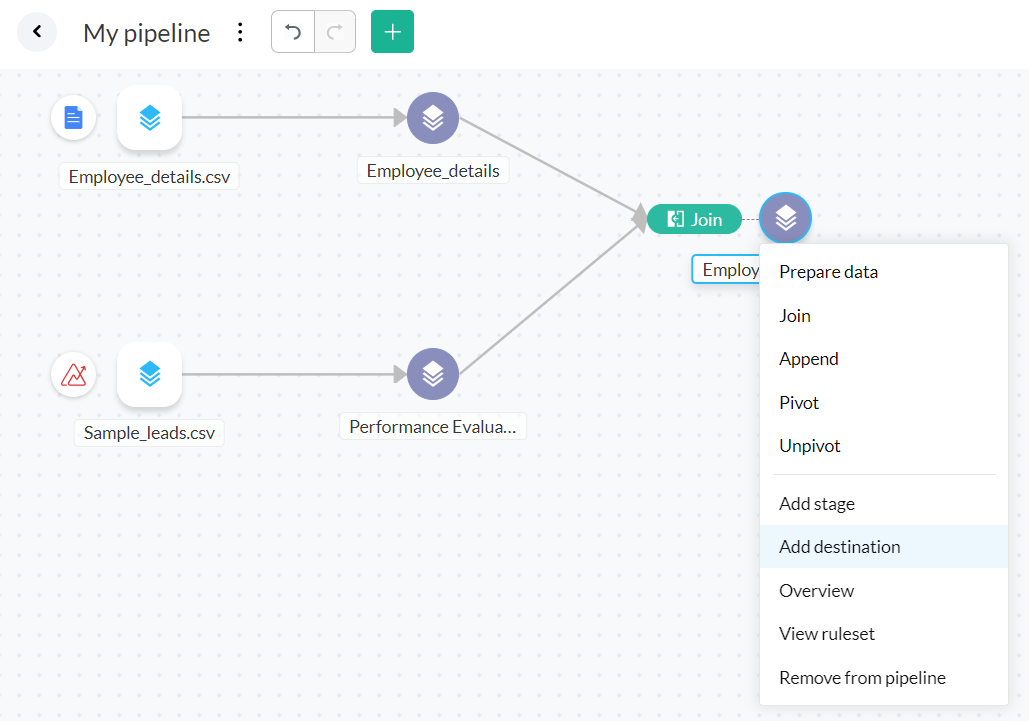
3. You can search for Zoho Analytics under the All destinations tab or filter it using the Zoho Apps category, and click on it.
4. Choose the Organization and Workspace in Zoho Analytics to which you want to export your data.
5. If you want to create a new table select the New table option. You can choose the required Organization, Workspace and click Export.
Note: For
schedule and
backfill run, the first export will be done to a new table and the same table will be treated as an existing table for the subsequent exports and your data will be exported when the target match passes. You can view the target match errors once you run the pipeline or you can directly open the stage from the
Pipeline builder page.
6. Choose Existing table if you want to export data to an existing table. Select one from the list of tables available in Zoho Analytics.
Note: Exporting data to system tables is not supported.
7. Choose one of the below options to determine how to handle the data being exported to Zoho Analytics:
- Add rows at the end - Using this option, you can add only the newly imported records at the end of your data in Zoho Analytics.
- Delete existing rows and add - This option will delete the existing records in your table and add records newly.
- Add rows and replace if already exists - Using this option, you can update the records that match the selected column and insert those records that do not match the selected column.
Note: You can select a column to match existing records only when you choose the Add rows and replace rows if already exists option.
8. You can choose to include columns containing personal data by selecting the Include columns with personal data check box.
9. Save the destination configuration.
Check Target Matching
Navigate to the DataPrep Studio page of the stage where Zoho Analytics is set as the destination.
Click the target matching icon

at the top right corner and choose the
Show target option. Make sure the target matching is done to avoid export failure
. Click here to know more about target matching.
Now, after checking the target matching, you may want to try executing your pipeline using a manual run at first. Once you make sure manual run works, you can then set up schedule to automate the pipeline. Learn about the different types of runs
here.
Info: Each run is saved as a job. When a pipeline run is executed, the data fetched from your data sources will be prepared using the series of transforms you have applied in each of the stages, and then data will be exported to your destination. This complete process is captured in the
Jobs page.
10. If the manual run succeeds without any errors, your data will be exported successfully. If the manual run fails throwing the below target match error, you can fix them by completing the target matching steps.
Target matching is a useful feature in DataPrep that prevents export failures caused due to errors from the data model mismatch.
Target matching during export to Zoho Analytics
Target matching happens before the data is exported to the destination. Target matching is a useful feature in DataPrep that prevents export failures caused due to errors from the data model mismatch. Using target matching, you can set the required table in Zoho Analytics as the target and align the source dataset columns to match with your target table. This ensures seamless export of high quality data to Zoho Analytics.
Note: Target matching failure is not an export failure. Target matching happens before the data is actually exported to the destination. This way the schema or data model errors that could cause export to fail are caught beforehand preventing export failures.
When target match check fails
1. If the target match check fails during export, you can go to the
DataPrep Studio page, click the target matching icon

at the top right corner and choose the
Show target option. The target's data model is displayed above the existing source dataset. The columns in the source dataset are automatically aligned to match the columns in the target dataset, if found.
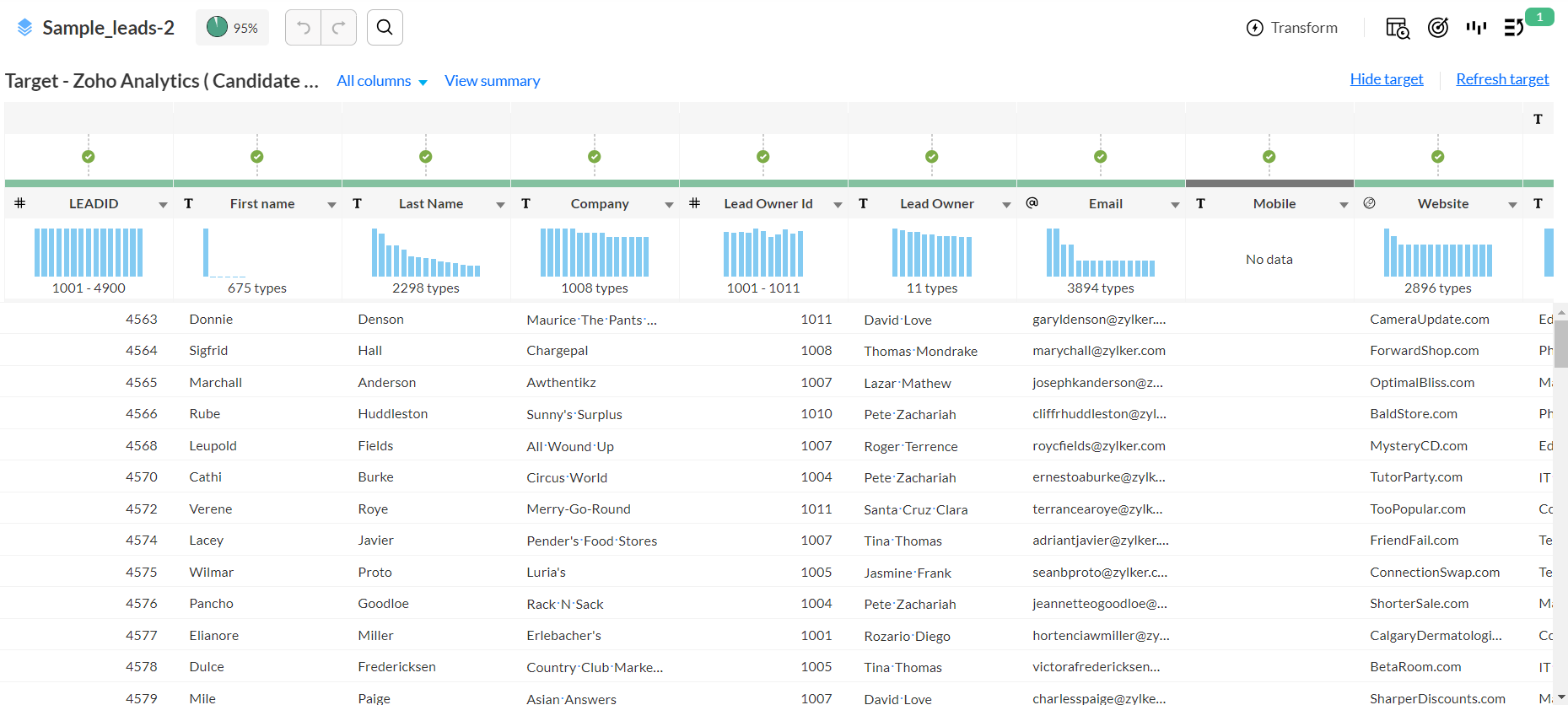
Target matching displays the different icons and suggestions on the matched and unmatched columns. You can click on these suggestions to quickly make changes to match the existing column with the target column. To make it easier for you to fix the errors, the target module in your Zoho Analytics is attached as a target to your data. You can view the mapping of your data with the table in the DataPrep Studio page along with the errors wherever there is a mismatch. You can hover over the error icons to understand the issue and click on them to resolve each error.
Note: All columns are displayed in the grid by default. However, you can filter out the required option by clicking the All columns link.
2. Click the View summary link to view the summary of the target match errors. The summary shows the different model match errors and the number of columns associated with each error. You can click on the required error columns and click Apply to filter out specific error columns.
Target match error summary
- The Target match errors section shows the errors and the number of columns associated with each error.
- The section at the top lists the error categories along with the number of errors in each category.
- You can click them to filter errors related to each category in the panel.
- In the default view, all columns are displayed. However, you can click any error category and get a closer look at the columns or view the error columns alone by selecting the Show only errors checkbox.
- Your filter selection in the Target match error summary will also be applied on the grid in the DataPrep Studio page.
Target matching errors
The errors in target matching are explained below:
Unmatched columns : This option shows all the unmatched columns in the source and target.
Note:
- The non-mandatory columns in the target can either be matched with a source column if available or ignored.
- The columns in the source that are missing in the target need to be matched or removed to proceed exporting.
When using the unmatched columns option, you can toggle the Show only mandatory columns option to see if there are any mandatory columns(set as mandatory in the target) and include them. You can also fix only the mandatory columns and proceed to exporting.
- Data type mismatch : This option displays the columns from the source having data types that do not match the columns in the target.
- Data format mismatch : This option displays columns from the source having date, datetime and time formats that differ from those in the target.
- Constraint mismatch : This option displays the columns that do not match the data type constraints of the columns in the target. To know how to add constraints for a column, click here.
Mandatory column mismatch: This option displays the columns that are set as mandatory in the target but not set as mandatory in your source.
Note: The mandatory columns cannot be exported to the destination unless they are matched and set as mandatory. You can click the

icon above the column to set it as mandatory. You can also use the
Set as mandatory (not null) check box under the
Change data type transform to set a column as mandatory.
- Data size overflow warnings : This option filters the columns with data exceeding the maximum size allowed in the target.
3. After fixing the errors you can go to the
Pipeline builder page and run your pipeline to export your data.
Once you make sure manual run works, you can then set up schedule to automate the pipeline. Learn about the different types of runs hereSchedule
Schedule configuration
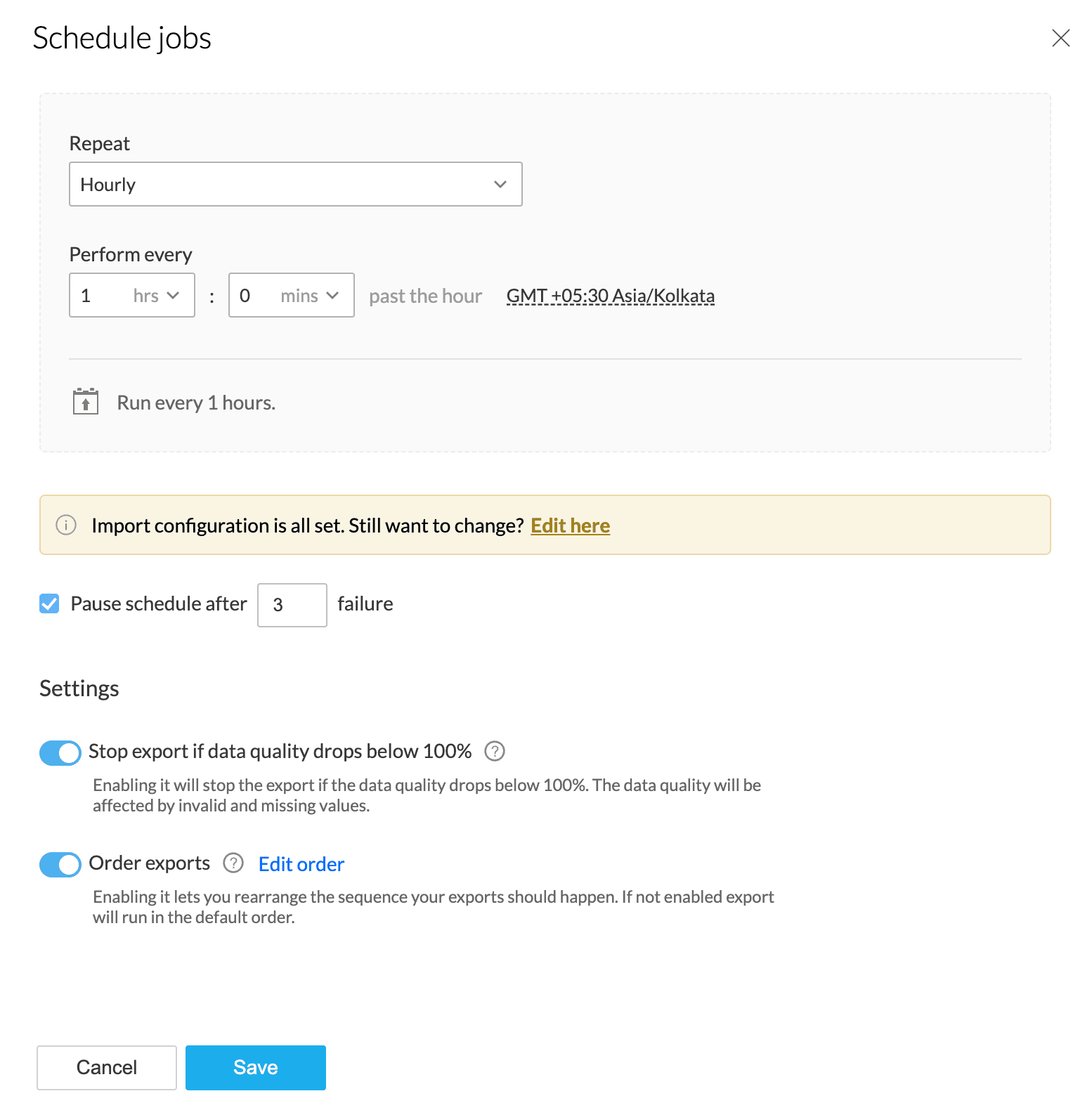
1. Select the Schedule option in the pipeline builder.
2. Select a Repeat method (hourly, daily, weekly, monthly) and set frequency using Perform every dropdown. The options of the Perform every dropdown change with the Repeat method. Click here to know more.
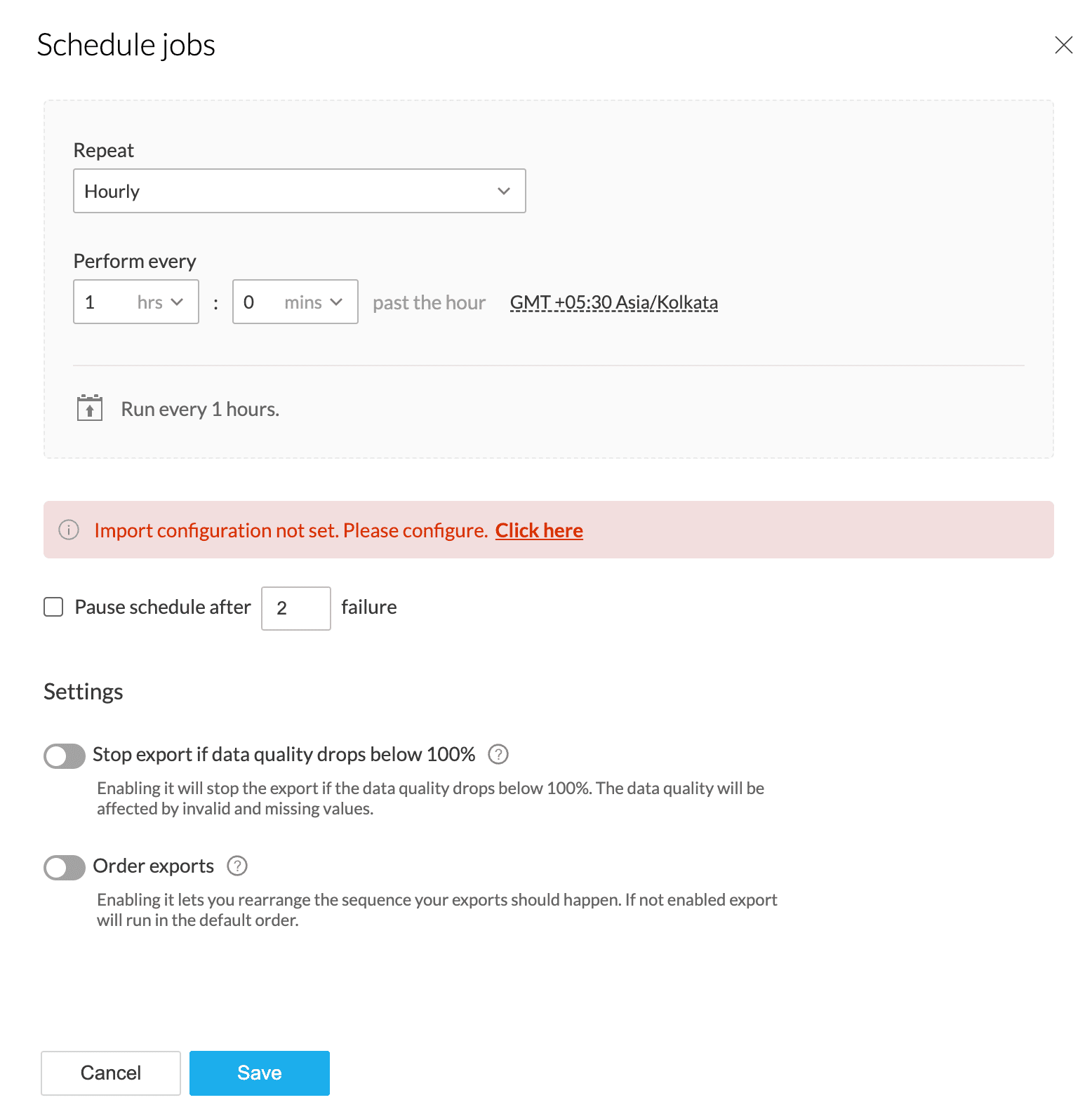
3. Select the GMT at which you want to import new data found in the source. By default, your local time zone will be selected.
4. Pause schedule after: This option allows you to choose to pause the schedule after n number of failures.
 Info: The range can be between 2-100. The default value is 2.
Info: The range can be between 2-100. The default value is 2.Schedule settings
Stop export if data has invalid values: Enabling this will stop the export when prepared data still has invalid values.
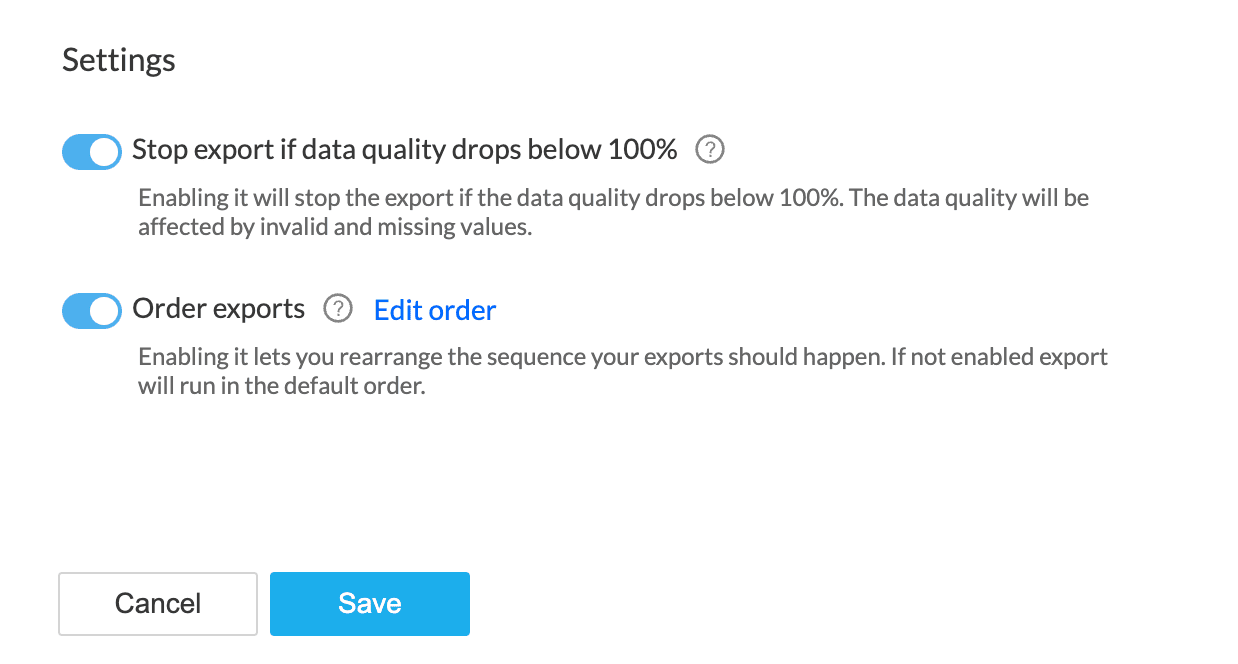
Order exports
You can use this option when you have configured multiple destinations and would like to determine in what order the data has to be exported to destinations.
If not enabled, export will run in the default order.
Note: This option will be visible only if you have added more than one destination in your pipeline.
To rearrange the order of your export destinations
1) Click the Order exports toggle
2) You can drag and drop to change the order of the destinations and then click Save.
Note: Click the Edit order link if you want to rearrange the order again.
8. After you configure the schedule configuration, click Save to execute the schedule. This will start the pipeline.
Each scheduled run is saved as a job. When a pipeline is scheduled, the data will be fetched from your data sources, prepared using the series of transforms you have applied in each of the stages, and then data will be exported to your destination at regular intervals. This complete process is captured in the job history.
9. To go to the jobs list of a particular pipeline, go to the  ellipses icon in the pipeline builder, and click on the Job history menu to check the job status of your pipeline.
ellipses icon in the pipeline builder, and click on the Job history menu to check the job status of your pipeline.
10. Click the required job ID in the Jobs history page to navigate to the Job summary of a particular job.
The Job summary shows the history of a job executed in a pipeline flow. Click here to know more.
11. When the schedule is completed, the data prepared in your pipeline will be exported to the configured destinations.
Info: You can also view the status of your schedules later on the Jobs page.
Note: If you make any further changes to the pipeline, the changes are saved as a draft version. Choose the Draft option and mark your pipeline as ready for the changes to reflect in the schedule.

After you set your schedule, you can choose to Pause schedule or Resume schedule, Edit schedule and Remove schedule using the Schedule Active option in the pipeline builder.
When you edit and save a schedule, the next job will be from the last schedule run time to the next scheduled data interval.
Limitations
You can export a maximum of 10 million records at a time
FAQs
1. If I rename a table in Zoho Analytics after scheduling a pipeline, will it affect the export to DataPrep?
No, renaming the table does not affect the export because the configuration in DataPrep maps to the table ID and not the table name. However, if you delete the table and create a new one with the same name, the schedule will fail, as the old table ID will no longer exist, even if the name matches.