Dataset transform consists of combining and transforming datasets to suit your needs. You can apply the following transforms in a dataset.
- Deduplicate
- Join
- Append
- Pivot
- Unpivot
- Calculated columns
- Derive dataset
- Mark as personal data
All the dataset transforms are present in the top bar transform menu
Deduplicate
You can remove duplicate records from your data using the Deduplicate transform. This can be done in two ways: row-wise and column-wise.
Row-wise
This method removes rows with duplicate data, allowing only unique rows to be present in your dataset.
To apply row-wise deduplication:
1. Click the Transform menu, click Deduplicate, then select Row-wise.
2. You can choose to ignore case and whitespace while removing duplicate rows.
Note: There could be instances where no duplicates were found in the sample dataset. You can still apply the rule to remove duplicates rows when the entire dataset is processed during export.
3. A live preview will be shown with the duplicate rows highlighted in red.
4. Click Remove duplicates.
Column-wise
You can also select single or multiple columns and choose to Deduplicate. The transform removes rows based on duplicate values present in the selected columns.
To apply column-wise deduplication:
1. Click the Transform menu, click Deduplicate then select Column-wise.
2. You can choose to ignore case and whitespace to find duplicates.
3. You can choose one of the two methods to deduplicate your dataset based on the selected column: Automatic deduplication or Manual conditions.
4. When you choose the Automatic deduplication method, DataPrep works for you to deduplicate your data based on the columns you've selected.
5. When you choose the Manual conditions method, you will need to enter the conditions and expressions and construct the 'if' statements. You can then select which rows to keep, or remove, within each of the duplicate cluster if the condition is true.
6. The following table lists the available
If conditions for all the data types.
Click here to know more about data types.
|
Text
|
Numeric
|
Datetime
|
Duration
|
Boolean
|
List
|
Map
|
|
contains
|
=equal to
|
= equal to
|
is smallest
|
is true
|
has value
|
has key
|
|
doesn't contain
|
!= not equal to
|
!= not equal to
|
is largest
|
is false
|
is empty list
|
is empty map
|
|
begins with
|
> more than
|
is earliest
|
= equal to
|
contains
|
is not empty list
|
is not empty map
|
|
ends with
|
< less than
|
is latest
|
!= not equal to
|
doesn't contain
|
is cell empty
|
is cell empty
|
|
is
|
>= more than or equal
|
is after
|
is cell empty
|
begins with
|
is cell not empty
|
is cell not empty
|
|
is not
|
<= less than or equal to
|
is before
|
is cell not empty
|
ends with
|
use regex
|
use regex
|
|
is cell empty
|
is smallest
|
on or after
|
use regex
|
is
|
use patterns
|
use patterns
|
|
is cell not empty
|
is largest
|
on or before
|
use patterns
|
is not
|
|
|
|
use regex
|
is cell empty
|
is cell empty
|
|
is cell empty
|
|
|
|
use patterns
|
is cell not empty
|
is cell not empty
|
|
is cell not empty
|
|
|
|
|
use regex
|
use regex
|
|
use regex
|
|
|
|
|
use patterns
|
use patterns
|
|
use patterns
|
|
|
7. You can also keep adding more conditions using the AND and OR operators to apply deduplication using a combination of conditions.
For example, you can write a condition that goes like this, "If the mail column contains zoho.com , keep those rows", i.e.,
Enter conditions to select which
If mail contains zoho.com
8. With the Advanced option, you can insert functions and provide conditions to remove duplicates.
9. Click the Preview button to see which rows will be removed during the transformation.
10. You can also select multiple columns for deduplication using (+) in Columns to de-duplicate.
Join
You can join two datasets together using common columns using the Join transform. Click
here to see a quick video of Join transform.
For example, consider a dataset which has the purchase data of a store and another dataset with their customer information. These datasets can be combined using a common column such as the customer ID to identify and match the records from both the datasets.
DataPrep offers all four types of joins: inner join, left join, right join, and outer join.
To perform a join transform:
1. Click the Transform menu, click Combine, then select Join.
2. In the Join dataset dialog, you can choose the dataset with which you are going to join the current dataset and the join type.
3. Select the dataset that you want to join your current dataset using the Choose a dataset to join drop-down.
A new dataset will be created with the result of the join transform.
DataPrep automatically calculates and shows the Join potential between the current dataset and other datasets from your workspace. The join potential is shown in percentage, making it easier for you to choose a dataset for the Join transform. It is a calculation based on various factors like the amount of matching data in a column and matching column names between the datasets.
4. Choose the type of join using the Join type option. You can also change the type of join from the Join type menu in the Transform panel.
5. Enter a name for the new dataset in the New dataset name box in the Transform panel.
6. Select the columns using which you want to join the two datasets in the Matched columns section.
Resolve repeated column names
7. Click the Preview button. The Resolve repeated column names dialog appears, if there are any columns with the same name. You will have to rename or delete them to resolve duplicate columns.
8. In the preview, you can unselect the columns that you do not want to include in the resultant dataset using the check boxes available in the column headers of the preview.
9. Click Join to join the two datasets.
10. Once you've successfully joined the two datasets, you can click Open the joined dataset.
11. If you wish to view the join configuration, you can click open the Data source configuration from the Ruleset pane from the joined dataset.
12. You can also click Edit join to update the join configuration.
Joins are typically used to combine two different datasets on the common items. Let's look into each type of join with an example.
Inner join
An inner join combines two datasets using common columns and discards all the unmatched rows.
The inner join is best represented as:
Let us take the example of the following datasets.
Orders dataset
Customers dataset
Order ID is the common column here. Inner join has combined the rows of the two datasets that shared values in the Order ID column and discarded the unmatched values from both Orders and Customers datasets.
Left join
A left join combines the current dataset with another dataset using common columns, and discards all unmatched rows from the other dataset.
Left join can be represented as:
Let's take the example of the following datasets:
Orders dataset
Customers dataset
Left join has combined the rows of the two datasets that shared values in the Order ID column. The unmatched values were only discarded from the Customers dataset.
Right join
A right join combines the current dataset with another dataset using common columns and discards all unmatched rows from the current dataset.
Right join can be represented as:
Let's take the example of the following datasets:
Orders dataset
Customers dataset
Right join has combined the rows of the two datasets that shared values in the Order ID column. The unmatched values were only discarded from the Orders dataset.
Outer join
An outer join combines two datasets using common columns and includes all the rows from both datasets (including all unmatched rows). An outer join can be represented as:
Let's take the example of the following datasets.
Orders dataset
Customers dataset
Outer join has combined the rows of the two datasets that shared values in the Order ID column. The unmatched values are kept from both Orders and Customers datasets.
Append
In DataPrep, you can append one dataset with another and create a new dataset using the Append transform.
Click here to see a quick video on Append transform.
To append datasets
1. Click the Transform menu, click Combine , then select Append.
Info: You can also click the  icon or right-click the stage in the Pipeline builder page and choose the Append transform.
icon or right-click the stage in the Pipeline builder page and choose the Append transform.
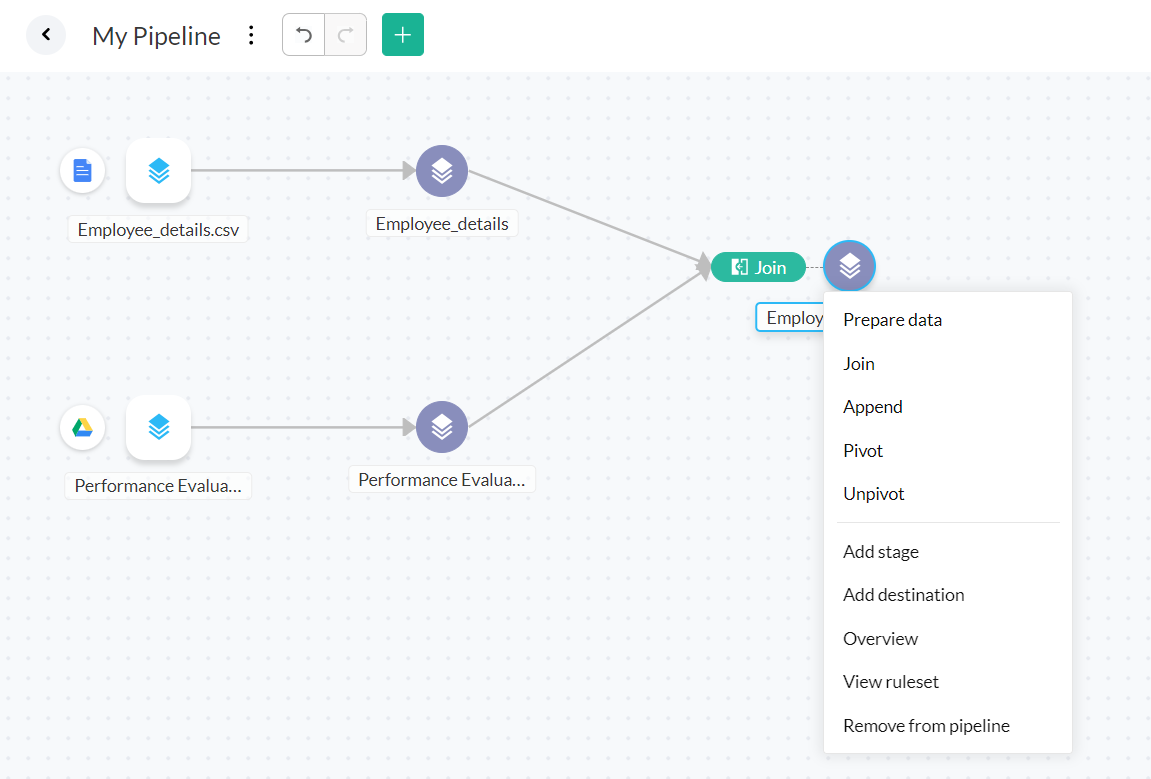
2. In the Append dataset dialog, you can choose the dataset that you want to append to the current dataset.
A new dataset will be created with the result of the append transform.
3. Enter a name for the new dataset in the New dataset name box in the transform panel.
4. DataPrep compares the column names of the two datasets and shows the unmatched columns so can choose to include or exclude them. For the matched ones, incoming data is added directly below the columns that have matched.
5. Click the Preview button and DataPrep will show a live preview of the append transform.
6. Click Append to apply the transform. Once you've successfully combined the two datasets by appending the rows, click Open the combined dataset.
7. If you want to edit the append configuration, you can open the Data source configuration from the Ruleset pane from the newly created dataset and edit the configuration.
Pivot
Pivot Table distributes data for easy consumption. It spreads out the data in long, winding tables by converting categories into columns. Pivot can be created by selecting the
Column ,
Row , and
Data fields. Click
here to see a quick video of Pivot transform.
To apply the pivot transform
1. Click the Transform menu and select the Pivot option. The Pivot pane will slide open to view.
Info: You can also click the icon or right-click the stage in the Pipeline builder page and choose the Pivot transform.
2. Select the fields that you want to convert to columns in the Columns section. Choose the fields to feature as rows in the Rows section and the fields with data in the Data section. Click here to know about the functions
Note: You can only choose fields with numerical data in the Data section.
3.
You can also select the Filters tab if you want to apply any filters. Using filters, you can selectively filter data based on the filter conditions applied over one or more columns. If you want to learn more about filters, click here .
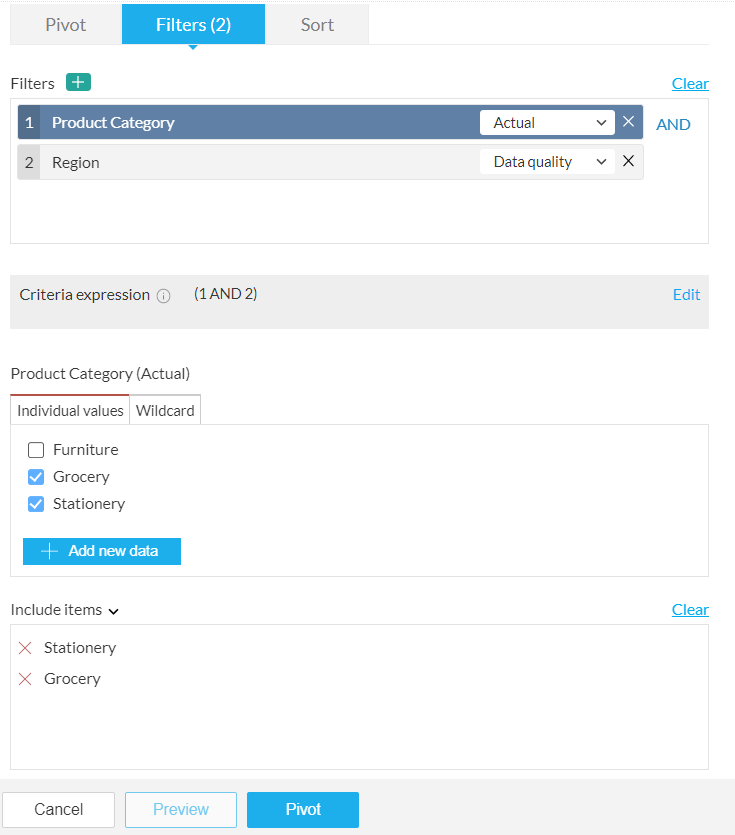
4. Select the Sort tab if you want to rearrange the order of your columns and rows. The fields added under the Pivot tab are also shown in the Sort tab. You can sort the data by rows and by columns using the By rows and By columns sections.
You can sort data in ascending or descending order, or perform a custom sort by selecting the options in the By columns and By rows sections.
You can view a preview of the table by clicking the Preview button. Click Reset to set back to the default selection (Ascending).
For example, you can select the Ascending and Descending options in the Product category and Region fields in the By columns sections, and select the Ascending option in the Customer Name filter in the By rows section to sort the Sales Data. The data sorted will look like as shown in the preview below.
You can also customize the arrangement by selecting the Custom option. You can drag and drop or use the up and down arrows to arrange the rows and columns.
Note: The filter and sort functionalities are optional.
5. You can add fields to the Data section, and you can choose one of the aggregate functions. The functions can get you the sum, count, average, etc. depending upon the data type of the fields added. The list of functions available for each data type is given in the table below.
|
Datatype
|
Functions
|
|
Number
|
Sum
Maximum
Minimum
Average
Standard deviation
Median
Mode
Percentile
Variance
Count
Distinct count
|
|
Text
|
Count
Distinct count
|
|
Date
|
Count
Distinct count
Maximum date
Minimum date
|
|
List
|
Count
Distinct count
|
|
Map
|
Count
Distinct count
|
 Note: The functions for the list data type counts the values and t he functions for the map data type counts the keys.
Note: The functions for the list data type counts the values and t he functions for the map data type counts the keys.
6. Click the Preview button and DataPrep will show a live preview of the pivot transformation.
7. When two or more fields are selected in the Columns box, the column names are joined using a dash or hyphen (-).
8. In the new dataset, you can open the data source settings from the Ruleset pane and edit the pivot configuration.
9. Click Pivot to apply the pivot configuration to your dataset.
Unpivot
Unpivot converts columns to rows. The Unpivot transform is useful in condensing data and the data is often exported to analytics software for creating reports and dashboards. The result is saved as a new dataset when the transform is applied.
To apply unpivot transform:
1. Click the Transform menu and select Unpivot option.
Info: You can also click the icon or right-click the stage in the Pipeline builder page and choose the Unpivot transform.
2. Enter a name for the new dataset in the New dataset name field.
3. Select the columns to unpivot in the Columns to apply box. These are the columns that will be converted into rows.
4. A new column will be created using the column headers of the selected columns. Enter a name for this new column in the Column name for headers field.
5. The values under the columns selected will be added to a separate column. Provide a name for this column in the Column name for values field.
6. Click on the Preview button and DataPrep will show a live preview of the transformation.
7. Click Apply and apply the unpivot transform.
You can create new columns and customize them using the Formula column transform. Zoho DataPrep offers a variety of functions to suit your needs. Click here to know more about the functions.
To create a formula column
1. Click on the Transform menu and select the Formula column option.
2. Provide a name for new column name in the New column name field.
3. You can insert the functions in the Formula field by typing the function names, or use the intelliSense to complete the functions. You can also apply filters and search functions in the Click to insert functions section.
4. You can also click the
OpenAI ChatGPT tile to generate formula by sending prompts to ChatGPT.
Click here to know more.
5. You can add parameters to the formula, or use intelliSense to choose columns. You can also search for column names in the Click to insert columns section.
6. DataPrep shows a live preview of the changes made to the formula when you click on the Preview button.
7. Click Apply to apply the changes.
Derive dataset
The Derive dataset transform allows you to create a branch of your dataset from the last applied transform in your dataset. The new dataset will have the most recent state of your data with an empty ruleset.
To derive dataset
1. Click the Transform menu and select the Derive dataset option.
2. Enter a name for your derived dataset under the New dataset name field.
3. Click Apply to create your derived dataset.
Now you've successfully created the derived dataset. The newly created dataset will have the most recent state of your data with an empty ruleset.
4. You can choose to click Open and start using the new dataset.
5. You can click the Data source configuration in the derived dataset to view the source details of the parent dataset.
Mark as personal data
You can mark a column that contains PII (Personal Identifiable Information) or personal data and ePHI (Electronic Protected Health Information ) data using the Mark PII and ePHI data transform. You can also apply security methods on the columns to protect your data and choose to include or exclude these columns during export.
To mark columns with PII data or personal data
1. Click the Transform menu and select the Mark PII and ePHI data option.
 You can also right-click on a column and select the Mark PII and ePHI data option from the context menu.
You can also right-click on a column and select the Mark PII and ePHI data option from the context menu.
2. Add personal data columns to the Mark columns with personal data section.
3. Click Apply to mark the selected columns as personal data.
To mark columns with ePHI data or health data
1. Click the Transform menu and select the Mark PII and ePHI data option.
Info: You can also right-click on a column and select the Mark PII and ePHI data option from the context menu.
2. Add columns containing health data under the Mark columns with ePHI data section.
3. Click Apply to mark the selected columns as ePHI data columns.
To protect personal data or ePHI data during export
1. On the Pipeline Builder page, once you have completed creating your data flow and applying the necessary transforms in your stages, you can right-click a stage and select the Add Destination option.
2. From the side pane, you can choose the destination where you want to export data. For example, let us choose Files as the destination.
3. Choose the columns with personal data or ePHI data to be included during export using the corresponding check boxes.
Note : Columns not marked as personal data or ePHI data will be included by default.
4. Choose the required security method from the drop-down to protect your personal data and click Next.
There are three security measures that can be applied to the personal data or ePHI data columns. These security measures are used to protect sensitive data such as Personally Identifiable Information (PII).
Security measures to protect personal data or ePHI data
1. Data masking
Data masking hides original data with 'x' to protect personal information.
2. Data Tokenization
Data tokenization replaces each distinct value in your data with a random value. Hence the output is statistically identical to the original data.
3. None
You can select None if you do not want to use any security method.
Note :
1. Exporting datasets without securing personal data will be restricted if Secure data exports option is enabled in your organization's privacy settings. Click here to know more.
2. Based on the Compliance settings of your organization, exporting datasets with ePHI data may be restricted or, exporting datasets without securing ePHI data with security measures and password protection would be restricted. Learn more
5. Provide the required values, and click Export.
Note: You can also review how personal data or ePHI data is protected in all your workspaces under the Review personal data in all workspaces section. Click here to know more.
SEE ALSO
 Info: You can also click the
Info: You can also click the